
Récupérer des infos techniques sur la Freebox V5/Crystal
 Cet article a été publié il y a 9 ans 7 mois 16 jours, il est donc possible qu’il ne soit plus à jour. Les informations proposées sont donc peut-être expirées.
Cet article a été publié il y a 9 ans 7 mois 16 jours, il est donc possible qu’il ne soit plus à jour. Les informations proposées sont donc peut-être expirées.L’astuce d’aujourd’hui va vous permettre de faire un peu de statistiques sur votre ligne ADSL/VDSL Free. En effet, sur le modèle V5/Crystal de « box » les informations de connexion sont disponibles dans un fichier texte par une adresse web. On va donc voir comment en extraire à peu près tout ce qu’on veut, pour l’exploiter ensuite de différente manières.
Contexte
Pour l’exemple, j’ai une ligne assez instable, comprendre qu’il ne se passe pas une semaine sans que je subisse des désynchronisations, qui coupent la connexion pendant moins d’une minute, mais plus gênant, qui peuvent entraîner des variations dans le débit de synchronisation. Chez moi ça oscille entre un peu plus de 3000 et 3300 kb/s, et il m’est même arrivé une seule fois d’accéder à un débit d’un peu plus 3500kb/s. La variation du débit montant est plus faible, entre 980 et 1020kb/s. Mais c’est pareil qu’on soit à 5kms ou à 300m du central (merci l’ADSL). Et tout ça est du débit ATM, comptez un débit IP (ou débit réel) d’environ 83% de ce débit ATM. Joie.
Sur les Freebox V5 et Crystal (qui ne sont que des V5 dans des Tupperware), vous pouvez effectivement accéder aux statistiques de votre connexion ADSL/VDSL au moyen d’une simple page web (c’est le même lien pour tous les freenautes). Cette page est au format texte brut, ce qui, sans être la panacée, peut s’avérer très pratique car on sait analyser et manipuler ce format dans plusieurs langages de programmations différents. Le texte est mis en forme pour un affichage « propre », exemple avec l’encart « Adsl » chez moi :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Adsl : ====== Etat Showtime Protocole ADSL2+ Mode Interleaved Descendant Montant -- -- Débit ATM 3302 kb/s 980 kb/s Marge de bruit 6.70 dB 7.20 dB Atténuation 59.00 dB 23.10 dB FEC 5505 95666 CRC 221 0 HEC 10 1578 |
Je pratique couramment du PHP, du « Shell », et plus récemment du Python, bien que je ne sois pas encore aussi à l’aise avec ce dernier comparé aux deux autres. J’ai évité PHP, peu adapté pour de l’exécution en ligne de commande (notez que c’est quand même faisable). J’ai donc d’abord fait un premier jet en Shell, et ensuite, comme je cherchais une solution multiplate-formes, c’est Python qui a pris le relais.
Script Shell, pour Linux
La plupart des shells disponibles sous Linux regorgent de commandes intégrées qui permettent la manipulation et l’extraction de chaînes de caractères. On peut donc indépendamment récupérer quantité d’informations, et surtout les stocker pour traitement.
Donc j’ai cherché à relever, une fois toutes les quatre heures, pendant un mois, le débit de synchronisation. Chaque valeur relevée est ajoutée dans un fichier texte brut, accompagné de la date, ce qui permettra de faire un joli graphique par la suite. Pour récupérer la page brute, j’utilise wget (à installer si par le plus grand des hasards vous ne l’auriez pas déjà sous la main), que je filtre ensuite au moyen de grep, et enfin que je « découpe » au moyen de awk pour ne récupérer que le débit descendant. Le tout en chaînant les commandes au moyen de pipes (vous savez, les |). Voilà le script terminé :
|
1 2 3 4 5 6 |
#!/bin/bash cd /home DEBIT=`wget -q -O - http://mafreebox.freebox.fr/pub/fbx_info.txt | grep ATM | awk '{printf $3}'` DATE=`date +"%Y%m%d%H%M"` echo "$DATE - $DEBIT" >> suivifree.txt |
Détaillons un peu :
- wget -q -O – http://… : « -O – » (sans nom de fichier derrière) permet d’envoyer le résultat, en l’occurrence le fichier texte, sur la sortie standard (à l’écran quoi); -q permet de masquer les messages que wget affiche normalement (progression, débit, destination), donc au final on n’a réellement que le contenu texte de la page récupéré.
- Le premier pipe envoie ce texte à grep, à qui je demande de chercher la ligne contenant la chaine « ATM » (il n’y en a qu’une seule).
- Le deuxième pipe permet de transmettre cette ligne à awk, à qui je demande d’afficher le troisième élément de la ligne ($3). En effet, si l’on compte les « mots » de la ligne, on a « Débit », puis « ATM », puis le chiffre recherché. Rassurez-moi, vous savez compter jusqu’à trois n’est-ce pas ?
- La redirection « >> » de la dernière ligne permet d’ajouter le résultat à la fin du fichier, et créer celui-ci s’il n’existe pas encore.
Je vous laisse avec la page de manuel de date pour découvrir les possibilités de formats de date et temps. Ici, dans le fichier on obtiendra un résultat de la forme « 201411181200 – 3302 ».
Reste à automatiser tout ça. Personnellement, puisque j’ai laissé le script sur mon serveur (allumé 24/7), j’ai opté pour une tache cron. J’ai appelé mon script getdebit.sh, l’ai rendu exécutable (chmod +x) et comme je l’ai dit, je veux récupérer l’info toutes les quatre heures. J’appelle donc ma liste de tâches planifiées avec « crontab -e« , et j’ajoute ceci :
|
1 |
00 */4 * * * /home/getdebit.sh |
Pensez à modifier le chemin pour pointer vers le bon emplacement. Bien évidemment, j’ai la sale habitude de tout faire avec le compte root sur mon serveur, je vous invite donc à faire ça mieux (avec un utilisateur « standard », et donc de ne pas ranger ça dans /home), et adapter le chemin à la ligne « cd … » du début du script. Voire ranger le script et le fichier suivifree.txt dans un dossier à part histoire de ne pas trop mélanger les choses.
Et quand on a pas Linux ? Python entre en piste
En effet, le serpent est plus agile que la coquille, car contrairement à Bash ou d’autres shells, qui demandent de grosses manipulations pour pouvoir s’installer dans une fenêtre, on peut facilement installer Python sous Windows.
ALERTE : je me suis volontairement limité à Python 2.7, parce que c’est la version utilisée dans Debian Wheezy par défaut (2.7.3 pour être précis). Donc si vous utilisez une distribution qui utilise Python 3 par défaut (c’est le cas de Manjaro), il faudra faire attention à le lancer avec la commande python2. Les différences sont mineures, mais suffisamment importantes pour nécessiter des modifications.
Pour rappel, on a donc besoin de récupérer une page web, d’en extraire le débit, de récupérer la date et l’heure, de mouliner le tout et d’écrire dans un fichier. Contrairement au Shell ou je peux directement faire appel à wget, grep, awk, date et des redirections, en Python il va falloir utiliser un ou plusieurs modules externes. Pour la première étape, urllib2 semble LE candidat idéal.
Par contre, une fois récupéré, il est plus ardu d’extraire la ligne voulue, en vue de l’analyser. J’ai mis près de trois heures à trouver une méthode qui fonctionnait à base d’expressions régulières, ma bête noire quelque soit le langage d’ailleurs. Je butais inlassablement sur un « None » laconique m’indiquant qu’il ne trouvait pas ce que je voulais. Mais bon, j’ai fini par y arriver, comme quoi tout n’est pas perdu. Parcourir une documentation uniquement en anglais n’aide pas non plus. Bref, il nous faudra ici le module re (pour regular expression).
Ensuite, Python sait manipuler les fichiers texte aisément pour pouvoir écrire dans celui qui nous intéresse. Dans le même ordre d’idée, créer une « date » exploitable est assez simple (toujours si on n’oublie pas de regarder la doc), et c’est le module time qui nous servira alors.
Je préviens qu’une fois le délire sur la regex débloqué, j’ai fait joujou pour trouver le truc qui utilise le moins de variables possibles. Et c’est un peu plus difficile à lire, mais on y arrivera. Bref, après moults essais, et surtout d’innombrables erreurs, voici le résultat :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#!/usr/bin/python # -*- coding: utf-8 -*- import urllib2 import re import time brut = urllib2.urlopen("http://mafreebox.freebox.fr/pub/fbx_info.txt") debit = re.search(".*ATM.*", brut.read()).group().split()[2] date = time.strftime("%Y%m%d%H%M") suivi = open("suivifree.txt", "a") suivi.write("%s - %s\n" % (date, debit)) suivi.close |
J’avais prévenu que ça pourrait paraître plus obscur que pour le script shell, mais dites vous que ça pourrait être encore un peu plus illisible. On voit deux étapes principales, la collecte et extraction des informations (débit et date), puis l’écriture dans le fichier. La plus obscure des lignes est clairement celle qui permet d’obtenir le débit. Voyons voir les différentes étapes pour y parvenir :
- brut est un objet qui contient à la fois l’entête de la page, ainsi que le contenu. brut.read() permet de ne garder que celui-ci, sous forme de chaîne de caractères
- re.search(motif, contenu) est la fonction qui permet de chercher le motif dans un contenu. En l’occurrence, je demande la ligne qui contient le motif « .*ATM.* » (ATM avec quelque chose avant et après –les « .* »), dans le contenu brut.read(). Le résultat est un objet, contenant le résultat et sa position
- Comme le résultat de la recherche est un objet, on fait appel à la commande .group(), ce qui permet d’obtenir sous forme de chaîne de caractères la fameuse ligne
- .split() transforme la chaîne de caractères en liste de mots. On a donc la liste [« Débit », « ATM », « 3302 », « kb/s », …]
- Il ne nous reste dès lors plus qu’à sélectionner le troisième élément, et comme on compte à partir de zéro, c’est [2] qui désigne « 3302 » ([3] nous donnerait « kb/s »)
Voilà, à part le fait que j’ai préféré récupérer la page dans une variable dédiée (ce que j’aurais pu m’épargner), on a un fonctionnement très proche de l’enchainement grep | awk, en un peu moins lisible je l’avoue. La construction de la date quant à elle se passe de commentaires, je vous renvoie vers la doc pour les détails.
L’écriture dans le fichier est un peu plus complexe qu’en bash, mais finalement, on sait à quoi s’en tenir. Je demande, au travers de la variable suivi, d’ouvrir le fichier suivifree.txt, en mode « append » (« a »), ce qui permet, contrairement au mode « write », d’ajouter les nouvelles valeurs à la fin du fichier plutôt que d’écraser celui-ci. J’écris dans ce fichier suivant un motif particulier : ce motif dit « un élément, un tiret, un élément, un retour à la ligne », avec une liste qui dit que le premier élément sera le contenu de date, et le deuxième le contenu de debit. J’aurais tout aussi bien pu faire une concaténation standard : date + » – » + debit + « \n ». Pour finir on ferme le fichier (d’où le .close() final), parce qu’on essaie quand même de sauver les meubles et on fait les choses bien.
Concernant la planification, sous Windows c’est assez obscur, mais pas infaisable.
Exploitation
Un mois plus tard, vous avez un gros fichier texte. Personnellement, je l’ai récupéré, puis importé dans LibreOffice Calc. J’ai ensuite sélectionné les deux colonnes résultantes, puis créé un petit graphique qui permet de se rendre compte de la « stabilité » du bazar :
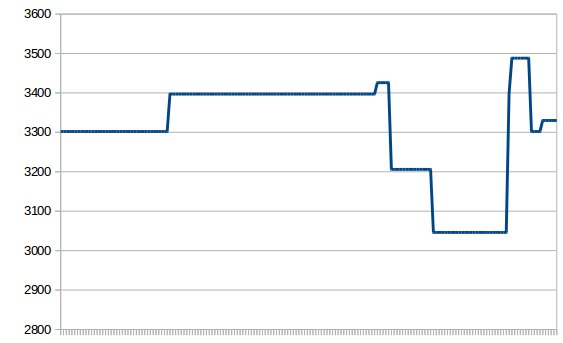
178 mesures composent ce graphique. Instable vous avez dit ?
Et pour info, voilà la liste des déconnexions/reconnexions durant le laps de temps :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
Journal de connexion adsl : --------------------------- Date Etat Débit (kb/s) -- -- -- 08/12/2014 à 08:51:48 Connexion 3330 / 997 08/12/2014 à 08:51:01 Déconnexion 07/12/2014 à 15:34:38 Connexion 3302 / 992 07/12/2014 à 15:33:42 Déconnexion 06/12/2014 à 14:32:38 Connexion 3488 / 988 06/12/2014 à 14:31:51 Déconnexion 06/12/2014 à 10:13:34 Connexion 3397 / 997 06/12/2014 à 10:12:47 Déconnexion 01/12/2014 à 22:48:54 Connexion 3046 / 985 01/12/2014 à 22:48:07 Déconnexion 29/11/2014 à 09:38:05 Connexion 3206 / 997 29/11/2014 à 09:37:01 Déconnexion 28/11/2014 à 14:37:33 Connexion 3426 / 988 28/11/2014 à 14:36:46 Déconnexion 16/11/2014 à 06:32:08 Connexion 3397 / 985 16/11/2014 à 06:31:21 Déconnexion 12/11/2014 à 18:17:29 Connexion 3302 / 985 12/11/2014 à 18:16:42 Déconnexion 08/11/2014 à 22:55:05 Connexion 3302 / 980 08/11/2014 à 22:54:17 Déconnexion 31/10/2014 à 07:44:07 Connexion 3206 / 980 31/10/2014 à 07:43:20 Déconnexion 30/10/2014 à 06:07:43 Connexion 3206 / 985 30/10/2014 à 06:06:56 Déconnexion 28/10/2014 à 02:35:13 Connexion 3258 / 988 28/10/2014 à 02:34:26 Déconnexion 27/10/2014 à 20:31:25 Connexion 3153 / 985 27/10/2014 à 20:30:38 Déconnexion |
On peut récupérer ce qu’on veut, en faire ce qu’on veut
Je tiens à préciser que le script, ne récupérant que le strict nécessaire, ne détecte pas les resynchronisations aboutissant au final sur le même débit, ce qui m’est arrivé. Sur la fameuse page complète, vous avez les dernières resynchronisations depuis le dernier démarrage de la Freebox. La fréquence pourrait vous surprendre 🙂 Par cet exemple, on comprend bien que pour l’instant, héberger le blog chez moi est irréel, comme je le disais lors de l’anniversaire. Et ça, sans même parler du débit montant. Et vu que la situation est similaire pour la moitié des français (même s’ils ne s’en rendent pas nécessairement compte, vu que leur connexion sert moins que la mienne), la route vers une « resymétrisation » d’Internet est encore longue.
La première fois que j’ai cherché à récupérer une des valeurs, ça concernait les erreurs FEC qui étaient particulièrement nombreuses, dues à une énorme instabilité de la ligne, qui était en très mauvais état, et qui s’accompagnait d’un débit réduit de près de 30%. Après huit mois de galère, Orange a fini par faire les travaux nécessaires sur le cuivre. Tout ça pour dire qu’à partir du moment où vous savez comment lire le fichier, et comment chercher dedans, libre à vous de récupérer ce que vous voulez, à la fréquence que vous voulez, et de traiter le résultat comme vous voulez. Et je vous ai montré deux moyens différents d’y arriver, le tout utilisable aussi bien sous Linux que sous Windows, elle est pas belle la vie ?
Bonjour, je cherche exactement la même chose pour tracer les
déconnexions… Ceci dit, j’aimerais l’exécuter à partir d’un
hébergement dédié sous linux et non à partir de ma propre connexion
Free. D’ouù ma question : est-il possible de récupérer le lien
mafreebox.free.fr en adresse ip interrogeable à distance ? Si j’y
arrive, je pourrai à chaque fois que j’ai une déconnexion intempestive
envoyer un mail en automatique à mon FAI. Histoire de faire comprendre
que ça fait dix ans que j’ai des déconnexions quotidiennes, que Free de
ne fait rien et que France Telecom non plus.
Impossible, il faut forcément être derrière sa box pour récupérer les informations. Perso, j’ai juste loggé la vitesse de synchro, ce que tu peux faire, par contre, c’est logger la date de dernière synchro.
Bonjour,
Des années plus tard… cette méthodo est elle toujours d’actualité?
A défaut, pour une freebox v5, connaissez-vous un moyen d’obtenir un historique des débits et déconnexions sous forme graphique éventuellement ?
Merci de votre aide
Bonjour,
La freebox v5 n’a pas évolué d’un poil, et juste avant de tomber malade mon raspberry pi récupérait toujours les infos (privilégier la version python). J’ai fait le choix de grafana, influxdb, j’en ai d’ailleurs fait un article : https://blog.seboss666.info/2016/07/monitoring-de-synchronisation-adsl-avec-telegraf-influxdb-grafana-et-un-peu-dhuile-de-coude/ 😉