diff un peu plus lisible
 Cet article a été publié il y a 7 ans 3 mois 4 jours, il est donc possible qu’il ne soit plus à jour. Les informations proposées sont donc peut-être expirées.
Cet article a été publié il y a 7 ans 3 mois 4 jours, il est donc possible qu’il ne soit plus à jour. Les informations proposées sont donc peut-être expirées.Vous avez peut-être déjà utilisé diff pour comparer le contenu de deux fichiers pour en connaître les différences. Mais il faut avouer que par défaut, l’affichage des résultats est assez peu lisible, un peu à l’image d’un dmesg. Fort heureusement, il est possible de lui demander d’être beaucoup plus « humain » dans ses réponses, voyons voir ce qu’il est possible de faire.
Rappel : comment ça marche par défaut
Lors de mon exemple d’utilisation de telegraf les yeux avisés auront remarqué que les scripts sont très proches. Voilà le résultat de diff par défaut :
|
1 2 3 4 5 6 7 |
pi@raspberrypi:/etc/telegraf/scripts $ diff download.py upload.py 8,9c8,9 < dlrate = re.search(".*ATM.*", brut.read()).group().split()[2] < print dlrate --- > ulrate = re.search(".*ATM.*", brut.read()).group().split()[4] > print ulrate |
J’avais prévenu, c’est dégueulasse, et encore l’exemple est assez simple ici. Donc on va chercher à améliorer tout ça.
Afficher le contexte
Le contexte, c’est afficher la ligne d’avant et la ligne d’après une modification pour bien expliquer ce qui a été modifié. Deux façons de s’y prendre, contexte copié, et contexte unifié. La différence entre les deux ? Le premier vous affiche chaque ligne modifié avec la ligne d’avant et la ligne d’après, le deuxième n’affiche qu’une seule fois ces lignes et regroupe les modifications entre celles-ci. Un exemple vaut mieux qu’un long discours, voyons donc respectivement ce qu’ils valent :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
pi@raspberrypi:/etc/telegraf/scripts $ diff -c download.py upload.py *** download.py 2016-07-10 10:39:40.776307293 +0000 --- upload.py 2016-07-10 10:40:02.647936707 +0000 *************** *** 5,9 **** import re brut = urllib2.urlopen("http://mafreebox.freebox.fr/pub/fbx_info.txt") ! dlrate = re.search(".*ATM.*", brut.read()).group().split()[2] ! print dlrate --- 5,9 ---- import re brut = urllib2.urlopen("http://mafreebox.freebox.fr/pub/fbx_info.txt") ! ulrate = re.search(".*ATM.*", brut.read()).group().split()[4] ! print ulrate |
|
1 2 3 4 5 6 7 8 9 10 11 |
pi@raspberrypi:/etc/telegraf/scripts $ diff -u download.py upload.py --- download.py 2016-07-10 10:39:40.776307293 +0000 +++ upload.py 2016-07-10 10:40:02.647936707 +0000 @@ -5,5 +5,5 @@ import re brut = urllib2.urlopen("http://mafreebox.freebox.fr/pub/fbx_info.txt") -dlrate = re.search(".*ATM.*", brut.read()).group().split()[2] -print dlrate +ulrate = re.search(".*ATM.*", brut.read()).group().split()[4] +print ulrate |
A noter que j’ai fait les tests sur deux machines différentes, l’une ma Manjaro, avec diff 3.5, l’autre le Raspberry Pi, avec Debian 8, et donc diff 3.3. Sur la plus récente, j’ai la possibilité supplémentaire de faire un --color pour afficher les différences avec des couleurs, un peu comme ici avec la coloraiton syntaxique, mais avec les – en rouge, et les + en vert (pratique quand on compare deux versions successives d’un fichier).
Et si on affichait sur deux colonnes ?
Attention, je recommande d’avoir un écran un peu large, encore qu’il semble tronquer par défaut (ceci dit ça permet de cibler les lignes différentes tout de même) :
|
1 2 3 4 5 6 7 8 9 10 |
pi@raspberrypi:/etc/telegraf/scripts $ diff -y download.py upload.py #!/usr/bin/python #!/usr/bin/python # -*- coding: utf-8 -*- # -*- coding: utf-8 -*- import urllib2 import urllib2 import re import re brut = urllib2.urlopen("http://mafreebox.freebox.fr/pub/fbx_i brut = urllib2.urlopen("http://mafreebox.freebox.fr/pub/fbx_i dlrate = re.search(".*ATM.*", brut.read()).group().split()[2] | ulrate = re.search(".*ATM.*", brut.read()).group().split()[4] print dlrate | print ulrate |
Vous aurez remarqué qu’il affiche systématiquement le contexte. Si vous voulez vous en passer, vous pouvez ajoute l’option --suppress-common-lines :
|
1 2 3 |
pi@raspberrypi:/etc/telegraf/scripts $ diff -y --suppress-common-lines download.py upload.py dlrate = re.search(".*ATM.*", brut.read()).group().split()[2] | ulrate = re.search(".*ATM.*", brut.read()).group().split()[4] print dlrate | print ulrate |
Moins chargé, mais moins précis également.
Et s’il n’y a pas de différence ?
Par défaut, ça ne dit rien (et ça renvoie un code de retour 0). Ca peut suffire pour des tests, notamment dans des scripts, mais d’un point de vue humain, c’est frustrant, un peu comme avec systemctl qui ne vous dit quelque chose que s’il y a un problème. Alors rendons-le un peu plus bavard :
|
1 2 3 4 |
pi@raspberrypi:/etc/telegraf/scripts $ cp download.py download2.py pi@raspberrypi:/etc/telegraf/scripts $ diff download* pi@raspberrypi:/etc/telegraf/scripts $ diff -s download* Les fichiers download2.py et download.py sont identiques |
C’est plus sympa comme ça non ?
Et en mode « graphique » ?
Carrément. Bon là c’est pas diff qui est mis à contribution, mais vim, avec la commande vimdiff, et là, une capture d’écran s’impose :
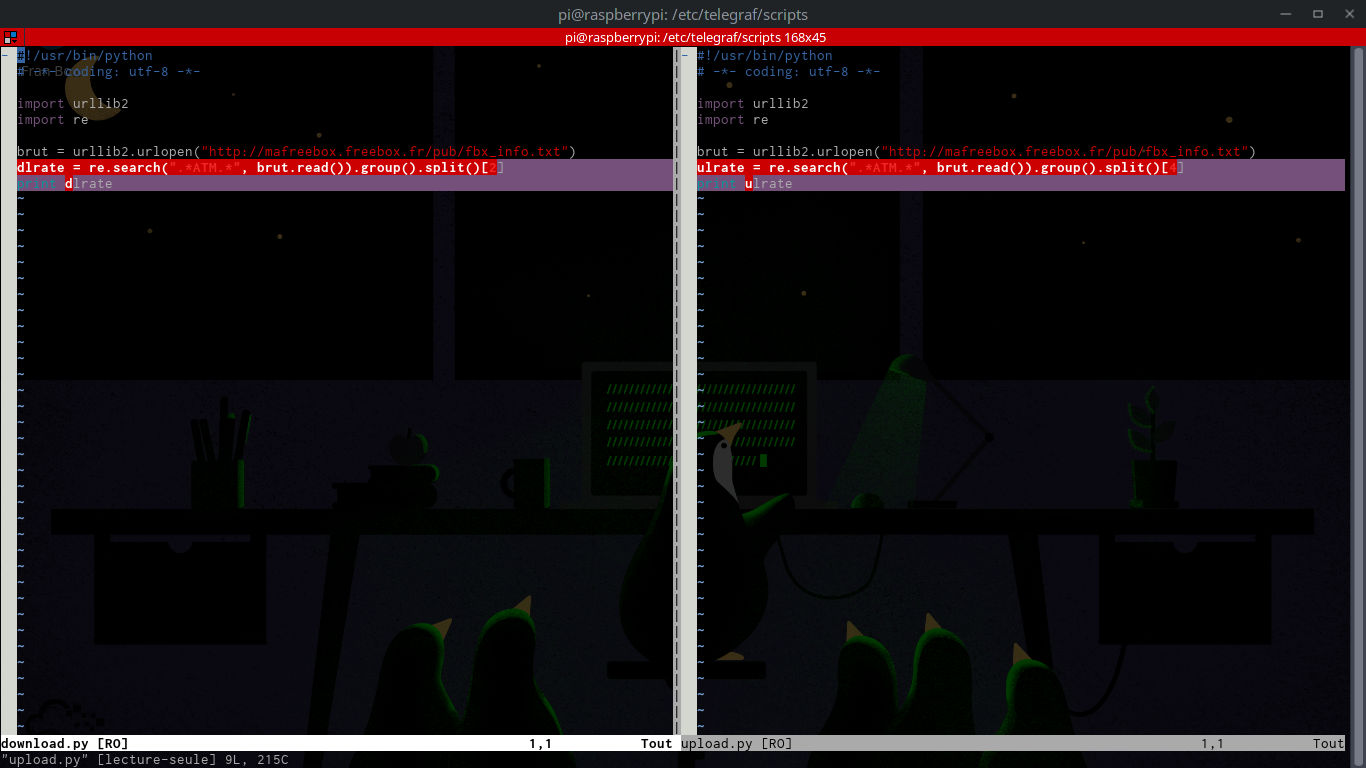 C’est le mode que je préfère, le plus clair.
C’est le mode que je préfère, le plus clair.
Vos IDE à la rescousse
J’ai présenté diff parce qu’on l’utilise souvent quand on est directement connecté à un serveur. Mais évidemment, les environnement de développement, les éditeurs de code, ainsi que les éditeurs de textes avancés proposent pratiquement tous, de manière native ou sous forme de plugin, une option de comparaison entre fichiers. Le plugin ‘compare’ de notepad++ par exemple ressemble fortement à vimdiff. A noter que git aussi embarque une option diff pour vérifier l’évolution d’un fichier entre la version courante et le dernier commit.
Bref, vous avez maintenant les moyens d’utiliser plus efficacement une commande diablement pratique, alors abusez-en 🙂
PS : juste avant la parution de cet article, le site HowToForge (que je recommande vivement) a publié la présentation d’un outil graphique appelé Meld qui permet de faire le travail dans une GUI pratique à utiliser.
Excellent article, merci beaucoup.
Je ne connaissait pas toutes ces possibilités…
À noter l’outil « meld » graphique qui est très bon pour afficher les diffs (voir les captures d’écran) http://meldmerge.org/
Il peut aussi comparer un dossier entier, et comparer 3 fichiers côte-à-côte.