Un exemple du mauvais usage de MongoDB
 Cet article a été publié il y a 9 ans 5 mois 5 jours, il est donc possible qu’il ne soit plus à jour. Les informations proposées sont donc peut-être expirées.
Cet article a été publié il y a 9 ans 5 mois 5 jours, il est donc possible qu’il ne soit plus à jour. Les informations proposées sont donc peut-être expirées.Lors de mes articles sur MongoDB, je concluais sur le fait qu’il ne conviendrait pas à tous les schémas de données. Je suis tombé sur un article très long, en anglais, qui explique très bien le problème avec une expérience très concrète, le début du développement de Diaspora (si ce réseau social décentralisé vous intéresse, vous pouvez vous inscrire sur Framasphere). Attention, c’est long, très long (regardez la barre de défilement sur le côté). Mais comme on dit, plus c’est long, plus c’est bon 🙂
Le titre original de cet article est « Why you should never use MongoDB ». C’est un peu trollesque, mais je n’en veux pas à l’auteure, Sarah Mei, développeuse Ruby et JavaScript à San Francisco. Elle sait certainement mieux que moi de quoi elle parle, et je pensais qu’il était important de partager son expérience avec ceux qui ne sont pas à l’aise avec l’anglais. Aussi, l’article a été écrit en 2013, et Diaspora a un peu changé depuis, en particulier dans l’interface.
Aussi, je ne suis pas un expert en traduction. Si jamais vous voyez une erreur par rapport à l’article original, n’hésitez pas à me corriger en commentaires 😉
Disclaimer : Je ne développe pas de moteur de base de données. Je développe des applications web. Je conduis 4 à 6 projets différents par an, donc je développe beaucoup d’applications web. Je vois des applications avec différents prérequis et différents besoin en matière de stockage de données. J’ai mis en service à peu près tous les modes de stockages dont vous connaissez l’existence, et quelques uns que vous ne connaissez probablement pas.
Il m’est arrivé de choisir le mauvais stockage parfois. Ceci est l’histoire d’une de ces fois – pourquoi on l’a choisi au départ, comment on a découvert qu’on s’est planté, comment on a corrigé le tir. Et tout ça, sur un un projet appelé Diaspora.
Le projet
Diaspora est un réseau social distribué avec une longue histoire. Trèèèès loin dans le temps au début 2010, quatre étudiants en Licence à l’université de New York ont fait une vidéo sur Kickstarter en demandant 10 000 $ pour passer l’été à concevoir une alternative distribuée à Facebook. Ils l’ont envoyé à des amis et à leurs familles, et ils ont croisé les doigts.
Apparemment ils ont touché une corde sensible. Un nouveau scandale sur les paramètres de confidentialité Facebook venait de sortir, et quand la poussière est retombé sur leur Kickstarter, ils avaient levé plus de 200 000 $ provenant de 6400 personnes pour un projet qui n’avait alors pas une seule ligne de code d’écrite.
Diaspora était le premier projet Kickstarter à grandement dépasser son objectif initial. Le résultat, un article dans le New York Times – qui a tourné un peu au scandale, parce que le tableau noir à l’arrière-plan de la photo de l’équipe présentait une blague douteuse, et personne n’avait remarqué avant le tirage. Dans le New York Times. Et c’est comme ça que j’ai entendu parler du projet pour la première fois.
Conséquence du succès de Kickstarter, les gars ont quitté l’école et déménagé à San Francisco pour commencer à écrire le code. Ils ont atterri dans mes bureaux. Je travaillais à Pivotal Labs à l’époque, et l’un des grands frères des gaillards y travaillait aussi, du coup Pivotal leur ont offert un bureau, une connexion Internet, et, bien sûr, l’accès au frigo (et à la bière). Je travaillais avec les clients dans la journée, et après en avoir fini avec ceux-ci, je contribuais du code les weekends.
Au final ils sont restés chez Pivotal pendant plus de deux ans. Après la fin du premier été, ils avaient déjà une implémentation minimale mais fonctionnelle (à peu de chose près), d’un réseau social distribué écrit avec Ruby on Rails et reposant sur MongoDB.
Beaucoup de jolis mots, donc démontons un peu le sujet.
« Réseau social distribué »
Si vous avez vu le film « Social Network », vous savez à peu près tout ce que vous avez besoin de savoir sur Facebook. C’est une application web, ça tourne sur un seul serveur logique, et ça vous permet de garder le contact avec des gens. Quand vous vous connectez, l’interface de Diaspora possède une structure un peu similaire à celle de Facebook :
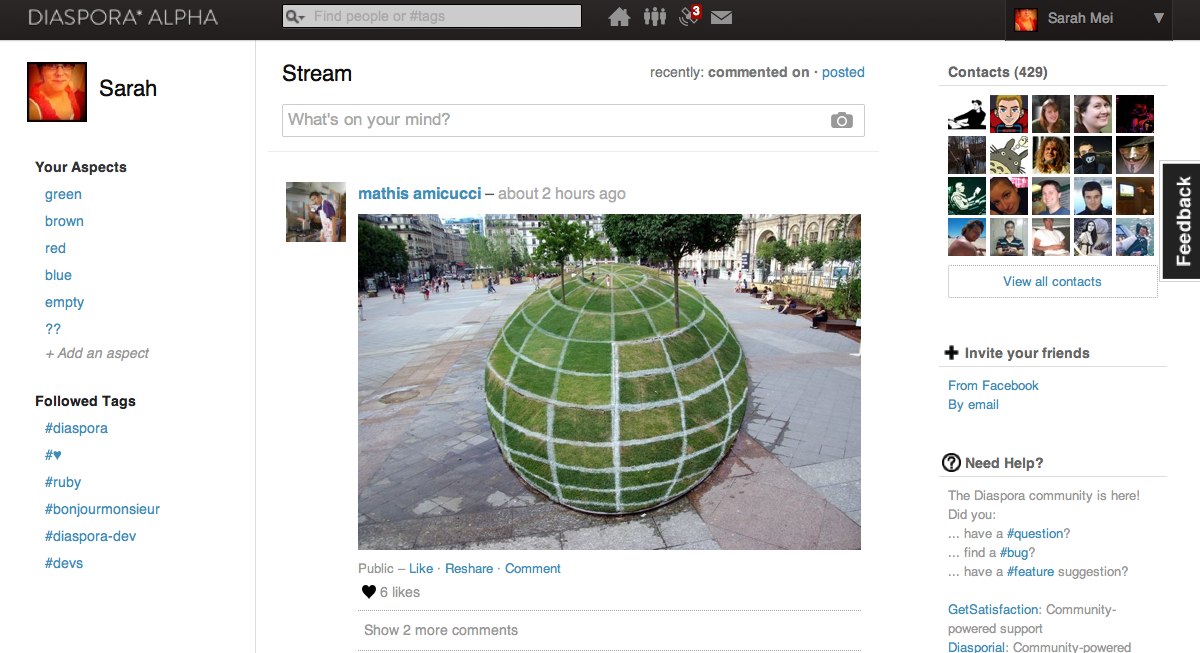
Exemple de l’interface de Diaspora
Vous avez un flux au milieu montrant l’activité de vos amis, et sur les côtés quelques activités et fonctions diverses que personne n’a jamais regardé. La principale différence technique entre Diaspora et Facebook est invisible pour les utilisateurs : la partie distribuée.
L’infrastructure de Diaspora n’est pas regroupée derrière une seule adresse web. Il y a des centaines de serveurs Diasporas indépendants. Le code est open source, donc, si vous le voulez, vous pouvez tenir votre propre serveur. Chaque serveur, qu’on appelle un pod (NdT : Framasphere et diaspora-fr sont deux pods Diaspora sur lesquels vous pouvez vous inscrire–l’un ou l’autre, peut importe), a sa propre base de données et son propre lot d’utilisateurs, et va inter-opérer avec tous les autres pods qui ont leur propre base de données et leur propre lot d’utilisateurs.
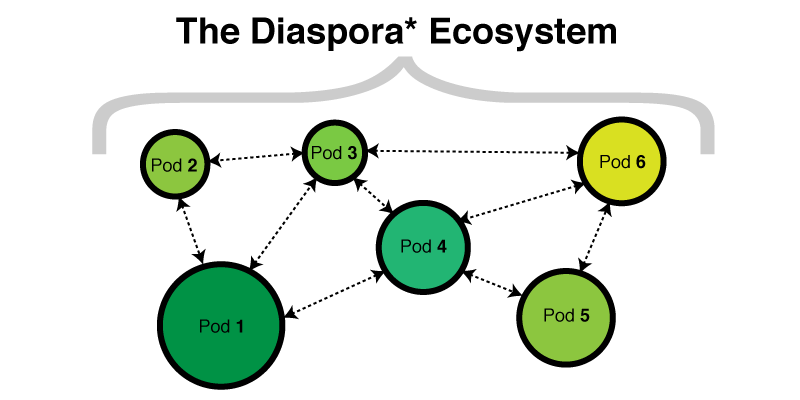
Les pods de taille différentes communiquent entre eux, sans point central.
Chaque pod communique avec les autres au travers d’une API basée sur HTTP. Une fois que vous avez créé un compte sur un pod, vous vous ennuierez jusqu’à ce que vous commenciez à suivre d’autre personnes. Et vous pouvez suivre des personnes qui sont sur votre pod, mais aussi des personnes qui sont sur d’autres pods. Quand une personne que vous suivez sur un autre pod poste un message, voilà ce qui arrive :
- La mise à jour est stockée sur le pod où se trouve l’auteur
- Votre pod est notifié de la mise à jour au travers de l’API
- La mise à jour est stockée dans la base de données de votre pod
- Vous regardez votre flux et voit le post en en question avec ceux des autres personnes que vous suivez.
Les commentaires fonctionnent de la même façon. Sur un seul message, certains commentaires peuvent provenir de personnes du même pod, et d’autres de personnes d’autres pods. Toutes les personnes qui ont la permission de voir le post verront les commentaires, juste comme vous vous attendez à les voir si tout le monde était sur un seul et même serveur.
Qui s’en soucie ?
Il y a des avantages techniques et légaux dans cette architecture. Le principal avantage technique c’est la tolérance aux pannes.

Ceci est un système à tolérance de panne que tout le monde devrait avoir.
Si n’importe lequel des pods tombe, ça ne fait pas tomber les autres. Le système survit au fractionnement du réseau. Il y a quelques implications politiques intéressantes à ça – par exemple, si vous êtes dans un pays qui coupe le pays du reste d’internet pour empêcher l’accès à Facebook et Twitter, votre pod local continue de se connecter aux personnes qui sont sur d’autres pods à l’intérieur du pays, même si vous ne pouvez plus « sortir » de celui-ci (NdT : Facebook tourne intégralement et uniquement aux Etats-Unis).
L’avantage « légal » est l’indépendance du serveur. Chaque pod est juridiquement indépendant des autres, gouverné par les lois de celui qui l’a installé (et de son pays). Chaque pod possède d’ailleurs ses propres conditions générales d’utilisation. Sur la plupart d’entre eux, vous n’abandonnez pas vos droits sur vos posts, contrairement à Facebook. Diaspora est un logiciel libre dans les deux sens (NdT: en anglais, logiciel libre se dit free software, free pouvant désigner libre ou gratuit, ou les deux), et la plupart des personnes qui tiennent des pods sont très soucieux de cette liberté.
Voilà l’architecture du système. Voyons dont de plus près l’architecture interne d’un seul pod.
C’est une application Rails
Chaque pod est une applications web Ruby on Rails accompagné d’une base de données, au départ MongoDB. Par certains côtés la base de code est une applications Rails ‘standard’ — interface utilisateur et moteur, du code Ruby, et une base de données. Mais par d’autres côtés il est tout sauf standard.
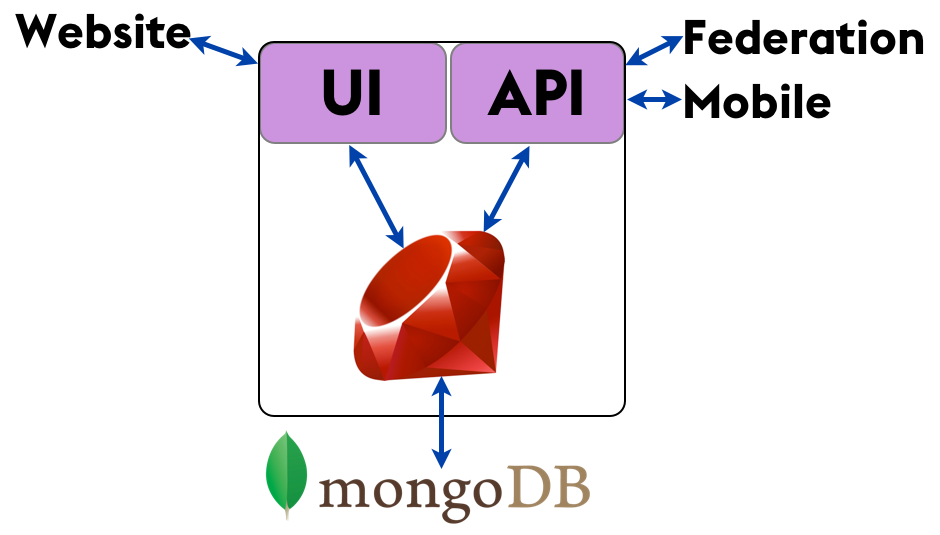
Structure interne d’un Pod Diaspora
L’interface utilisateur « visuelle » est évidemment celles que les utilisteurs du site web utilisent pour interagir avec Diaspora. L’API est utilisée par divers clients mobiles – c’est la partie standard – mais aussi pour la « fédération », le terme technique pour la communication inter-pod. (J’ai demandé où était auparavant l’accès des Romuliens, et je n’ai reçu que des yeux écarquillés). Donc la nature distribuée du système ajoute des couches à l’application qui ne sont pas présentes dans une application typique.
Et bien sur, MongoDB est un choix atypique pour le stockage des données. La grande majorité des applications Rails utilisent PostgreSQL ou, de moins en moins de nos jours, MySQL.
Voilà pour le code. Maintenant, regardons quelles données on doit stocker.
Je ne pense pas que ce mot signifie ce que vous pensez qu’il signifie
(oui j’ai eu du mal à traduire celui-là)
« Les données sociales » sont l’information à propos de notre réseau d’amis, leurs amis, leur activité. Conceptuellement, on le conçoit comme un réseau – un graphe « non-dirigé » dans lequel nous somme le centre, et nos amis gravitent autour de nous.

Photos provenant de rubyfriends.com. Merci à Matt Rogers, Steve Klabnik, Nell Shamrell, Katrina Owen, Sam Livingston-Grey, Josh Susser, Akshay Khole, Pradyumna Dandwate, et Hephzibah Watharkar pour leur contribution à #rubyfriends!
Quand on stocke des données sociales, on stocke la topologie de ce graphe, ainsi que l’activité qui est liée à ses éléments. Depuis quelques années, la pensée dominante est que les données sociales ne sont pas relationnelles, et que si vous stockez ça dans une base de données relationnelles, vous vous plantez.
Mais quelles sont les alternatives ? Certains disent que les base de données « graphiques » sont plus naturelles, mais je ne vais pas en parler ici, car ce sont des bases de données trop spécifiques pour être mises en production. D’autres avancent que les bases de données orientées documents sont parfaites pour les données sociales, et qu’elles sont suffisamment répandues maintenant pour être réellement utilisées. Donc regardons pourquoi les gens pensent que les données sociales conviennent mieux à MongoDB qu’à PostgreSQL.
Comment MongoDB stocke ses données
MongoDB est une base de données orientée document. Au lieu de stocker des données dans des tables constituées de lignes individuelles, comme une base de données relationnelle le fait, il stocke vos données dans des collections faites de documents individuels. Dans MongoDB un document est un gros blob JSON sans format ou schéma particulier.
Admettons que vous avez une série de relations que vous devez modéliser. C’est assez proche d’un projet que j’ai mené chez Pivotal et qui utilisait MongoDB, et c’est le meilleur cas d’usage que j’ai vu pour de l’orienté document.
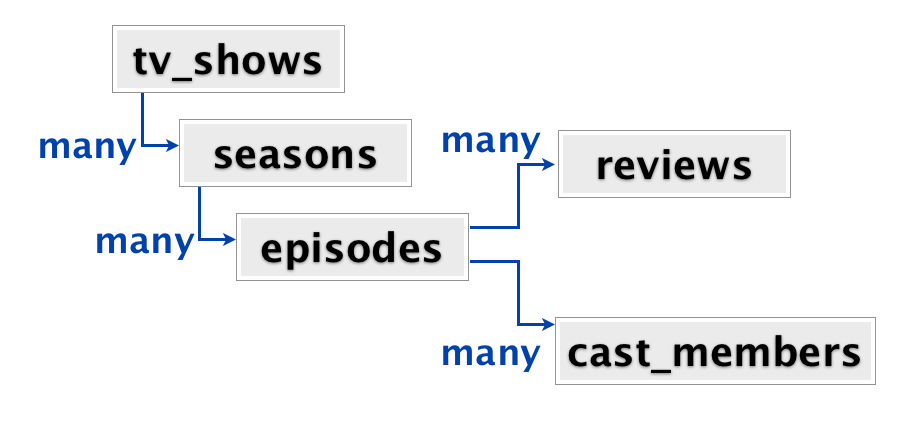
À la racine, un « jeu » de séries TV. Chaque série à plusieurs saisons, chaque saison a plusieurs épisodes, et chaque épisode a plusieurs critiques et plusieurs acteurs. Quand les utilisateurs viennent sur le site, typiquement ils vont sur la page en particulier d’une des séries TV. Sur cette page ils voient toutes les saisons et tous les épisodes et toutes les critiques et tous les acteurs de cette série, le tout sur une seule page. D’un point de vue de l’application, quand l’utilisateur visite la page d’une série, on veut récupérer toute l’information raccordée à cette série.
Il y a plusieurs façons de modéliser ces données. Dans une base relationnelle typique, chacune des « boites » du graphe serait une table. Vous auriez une table tv_shows, une table seasons, avec une « foreign key » dans tv_shows, une table episodes avec une « foreign key » dans seasons, et des tables reviews et cast_members avec des « foreign keys » dans episodes. Donc pour avoir toute l’information sur une série, vous devriez opérer une jointure sur cinq tables.
On peut aussi modéliser ces données comme un jeu de documents imbriqués. Les informations sur une série télé en particulier serait une énorme structure de données clé/valeur imbriquées. Dans une série TV, il y a un tableau des saisons, chaque saison étant aussi un document. Dans chaque saison, un tableau d’épisodes, et ainsi de suite. Voilà comment MongoDB modélise les données. Chaque série TV est un document qui contient tout l’information dont nous avons besoin pour cette série.
Voici un exemple de document pour la série Babylon 5 (NdT: je vous la recommande chaudement).

Il y a quelques méta-données comme le titre et ensuite un tableau de saisons, chaque saison est un document avec méta-données et tableau d’épisodes. En conséquence, chaque épisode a des méta-données et des tableaux pour les critiques et les acteurs.
Basiquement c’est une énorme structure fractale.

Des sets de sets de sets de sets. Miam.
Toutes les données dont nous avons besoin pour une série TV sont regroupées dans un seul document, donc il est très rapide de récupérer ces informations d’un seul coup, même si le document est très gros. Il y a une série TV aux USA appelée General Hospital, qui a plus de 12000 épisodes au compteur sur plus de 50 saisons. Sur mon ordinateur portable, PostgreSQL prend environ une minute pour extraire les informations des 12000 épisodes quand MongoDB ne prend qu’une fraction de seconde.
Donc, par bien des aspects, cette application présentait le parfait cas d’usage pour un stockage en documents.
OK, mais quid des données sociales ?
Bon. Quand on en vient à un réseau social, il n’y a qu’une chose qui importe sur la page : votre flux d’activité. La requête pour le flux d’activité récupère tous les posts des personnes que vous suivez, triée du plus récent au plus ancien. Chacun de ces posts a des informations imbriquées, comme des photos, les likes, les repartages, et les commentaires.
La structure imbriquée du flux d’activité est assez similaire à celle qu’on a analysé pour les séries TV :
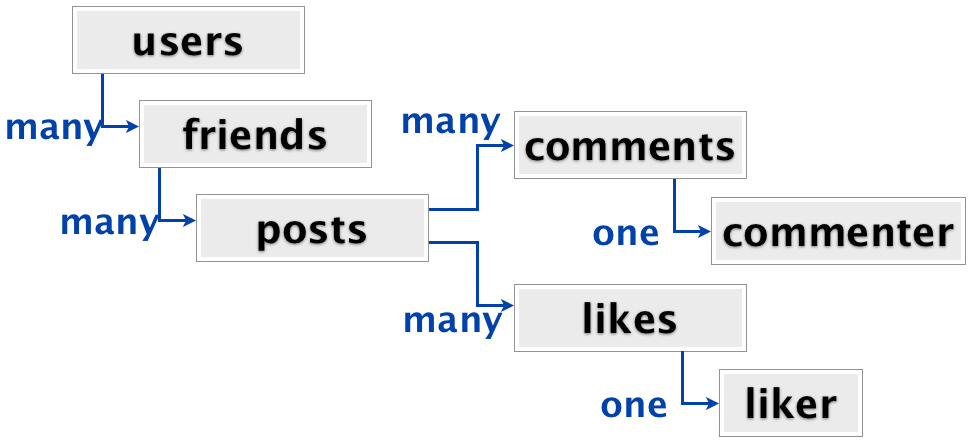
Les utilisateurs ont des amis, les amis ont des posts, les posts ont des commentaires et des likes, et chaque like a un « liker ». D’un point de vue relationnel, ce n’est pas beaucoup plus compliqué que les séries TV. Et tout comme les séries TV, on veut récupérer toutes ces données en une fois, juste après la connexion de l’utilisateur. Par ailleurs, dans un stockage relationnel, avec les données complètement normalisées, ça serait une jointure à sept tables qu’il faudrait opérer.
Une jointure à sept tables. Ouch. D’un seul coup, stocker le flux d’activité de chaque utilisateur comme une structure énorme dénormalisée, plutôt que faire cette jointure à chaque fois, semble très attrayante.
En 2010, quand l’équipe Diaspora a pris cette décision, les articles d’Etsy sur l’utilisation des stockages de document ont fortement influencé la décision, même si depuis ils sont passés à autre chose pour le stockage de données. Par ailleurs, Cassandra (par Facebook) alimentait elle aussi les conversations sur le fait de se passer de base de données relationnelles. Diaspora avait choisi MongoDB pour les données sociales parce que c’était dans l’air du temps. Ce n’était pas un choix déraisonnable à l’époque, étant donné les informations dont ils disposaient.
Qu’est-ce qui pouvait mal se passer ?
Il y a une différence importante entre les données sociales de Diaspora et les données de séries TV que personne n’avait remarquée au départ.
Avec les séries TV, chaque élément du diagramme relationnel est d’un type différent. Les séries TV sont différentes des saisons qui sont différentes des épisodes qui sont différentes des critiques qui sont différentes des acteurs. Aucun n’est d’ailleurs un sous-type d’un autre type.
Avec les données sociales, certains de ces éléments sont du même type. En fait, tous les éléments en vert sont des utilisateurs :

Un utilisateur a des amis, et chaque ami est un utilisateur. Ou pas, parce que c’est un système distribué (une caractéristique qui apporte sa propre couche de complexité qu’on va écarter aujourd’hui). De la même façon les commentateurs et les likers peuvent aussi être des utilisateurs.
Cette duplication du type rend bien plus difficile la dénormalisation dans le flux d’activité dans un seul document. Parce qu’à différents endroits du document, vous pourriez faire appel au même concept – dans le cas présent, le même utilisateur. L’utilisateur qui a liké un post dans votre plux d’activité en a peut-être commenté un autre.
Dupliquez les données qui dupliquent des données
On peut représenter ça dans MongoDB de plusieurs façons. La duplication est l’option facile. Toute l’information d’un ami est copiée et sauvegardé dans le like du premier post, et une copie séparée est encore stockée dans le commentaire sur le second post. L’avantage c’est que toutes les données sont présentes où vous en avez besoin, et vous pouvez toujours stocker le flux dans un seul document.
Voici à quoi ressemble ces données complètement dénormalisées :

Ici, nous avons des copies des données des utilisateurs embarquées. C’est le flux de Joe, avec une copie de ses données incluant son nom, son URL. Son flux, juste en dessous, contient le post de Jane. Joe a liké le post de Jane, alors dans les likes du post, on a une copie séparée des données de Joe.
C’est attirant : toutes les données dont vous avez besoin sont localisées où vous en avez besoin. Vous pouvez voir pourquoi c’est dangereux : Mettre à jour les données d’un utilisateur veut dire qu’on devra parcourir tous les flux d’activité où les données apparaissent pour mettre à jour toutes ces copies dans ces lieux différents. C’est très enclin à l’erreur, et souvent mène à des données inconsistantes et des erreurs mystérieuses, en particulier quand on traite des suppressions.
N’y a-t-il aucun espoir ?
Il y a une autre approche pour traiter le problème avec MongoDB, qui est plus familière si vous avez un passé « relationnel ». Plutôt que dupliquer les données, vous stockez des références à l’utilisateur dans le flux d’activité.
Avec cette approche, au lieu d’embarquer les données utilisateur où vous en avez besoin, vous attribuez un identifiant (ID) à l’utilisaeur. Une fois que les utilisateurs ont des IDs, vous stockez cet ID dans chaque endroit où vous embarquiez précédemment les copies. Ces nouveaux IDs sont en vert sur l’image suivante :

MongoDB utilise en fait les IDs BSON, mais pour l’exemple ça suffira
Ceci élimine le problème de duplication. Quand les données utilisateurs changent, il n’y a qu’un seul document qui est réécrit. Cependant, on a créé un nouveau problème. Parce nous avons sorti certaines données du flux d’activité, on ne peut plus le créer à partir d’un seul document. C’est moins efficace et plus complexe. Construire un flux d’activité nous demande d’1) récupérer le document du flux et 2) récupérer tous les documents utilisateurs pour remplir noms et avatars.
Ce qu’il manque à MongoDB c’est une opération de jointure similaire à MySQL, ce qui permet d’écrire une seule requête qui amalgame le flux d’activité et les utilisateurs qui sont référencés dans ce flux. Comme MongoDB ne possède pas ce mécanisme, vous vous retrouvez à faire ce mélange au niveau de l’application.
Des données dénormalisées simples
Revenons rapidement sur les séries TV. Les relations au sein d’une série ne sont pas très complexes. Parce que tous les éléments du diagramme relationnel sont des entités différentes, la requête entière peut être dénormalisée dans un seul document sans duplication et sans références. Dans cette base de données de documents, il n’y a pas de lien entre les documents. Il n’y a pas besoin de jointures.
Dans un réseau social par contre, rien n’est indépendant. À tout moment vous voyez quelque chose qui ressemble à un nom ou une image, vous vous attendez à pouvoir cliquer dessus et voir l’utilisateur derrière, son profil, ses messages. Une application pour séries TV ne fonctionne pas pareil. Si vous êtes sur l’épisode 1 de la saison 1 de Babylon 5, vous ne vous attendez pas à pouvoir cliquer pour découvrir l’épisode 1 de la saison 1 de General Hospital.
Ne. Liez. Pas. Les. Documents.
Une fois qu’on a commencé à faire des jointures très laides dans MongoDB manuellement dans le code de Diaspora, on a compris que c’était le premier signe de gros soucis. C’était un signe que notre structure de données était en fait relationnelle, qu’il y avait de la valeur dans cette structure, et qu’on travaillait contre le concept basique d’un stockage de données en documents.
Quand vous dupliquez des données critiques (beurk), ou utilisez des références et opérez des jointures dans le code de votre application(double beurk), quand vous avez des liens entre les documents, vous avez surestimé MongoDB. Quand les gars de MongoDB disent « documents », de bien des manières, ils signifient des choses que l’on peut imprimer sur un bout de papier et tenir du bout des doigts. Un document peut avoir une structure interne –entêtes, sous-entêtes, paragraphes, pieds de pages– mais ils ne contiennent pas de liens vers d’autres documents. C’est un morceau indépendant de données semi-structurées.
Si vos données ressemblent à ça, vous avez des documents. Bravo ! C’est une bonne raison d’utiliser MongoDB. Mais s’il y a une raison d’avoir des liens entre les documents, alors vous n’avez pas de document. MongoDB n’est pas la bonne solution pour vous. Ce n’est certainement pas la bonne solution pour des données sociales, où les liens entres documents sont l’information la plus critique du système.
Donc les données sociales ne sont pas orientées document. Est-ce que ça signifie que c’est en fait… relationnel ?
Encore ce mot
Quand les gens disent « les données sociales ne sont pas relationnelles », ce n’est pas exactement ce qu’ils veulent dire. Ils pensent l’une des deux choses suivantes :
1. Conceptuellement, les données sociales sont plus un graphe qu’un groupe de tables »
C’est absolument vrai. Mais il y a en fait quelques concepts dans le monde qui sont naturellement construits comme des tables normalisées. On utilise cette structure car elle est efficace, parce qu’elle évite la duplication, et parce que quand ça devient lent, on sait comment corriger ça.
2. C’est plus rapide de récupérer toutes les données d’une requête sociale quand elles sont dénormalisées dans un seul document.
C’est aussi absolument vrai. Quand vos données sociales sont dans un stockage relationnel, vous devez joindre plusieurs tables pour extraire le flux d’activité pour un utilisateur en particulier, et ça devient de plus en plus lent à mesure que vos tables grossissent. Cependant, on a une solution bien connue à ce problème. Ça s’appelle la mise en cache (NdT: désolé, même Stéphane Bortzmeyer a des problèmes à le traduire ce terme).
À la conférence All Your Base à Oxford plus tôt dans l’année, où j’ai donnée une version « parlée » de cet article, Neha Narula a donné un excellent exposé sur la mise en cache que je vous recommande une fois qu’il sera en ligne. Dans n’importe quel cas, mettre en cache devant un stockage de données normalisées est un problème complexe mais bien compris. J’ai vu des projets « cacher » les données d’un flux d’activité dans des bases de données documents comme MongoDB, ce qui permet de récupérer les données bien plus rapidement. Le seul problème qu’ils ont est alors l’invalidation du cache.
Il y a deux problèmes en informatique : l’invalidation de cache et nommer les choses.
Phil Karlton
Il apparaît que l’invalidation du cache est en fait assez difficile, Phil Karlton a écrit la plupart d’SSLv3, X11, et OpenGL, donc il connaît quelques trucs en matière d’informatique.
Invalidation du cache « As a service »
Qu’est-ce que l’invalidation du cache, et pourquoi est-ce si difficile ?
L’invalidation du cache consiste juste à savoir quand une partie des données sauvegardées sont périmées, et ont besoin d’être mises à jour ou remplacées. Voici un exemple typique que je vois tous les jours dans les applications web. On a un stockage « à l’arrière », PostgreSQL ou MySQL, et à l’avant une couche de mise en cache, Memcached ou Redis. Les requêtes pour lire le flux d’activité d’un utilisateur vont dans le cache plutôt que sur la base de données directement, ce qui les rend plus rapides.
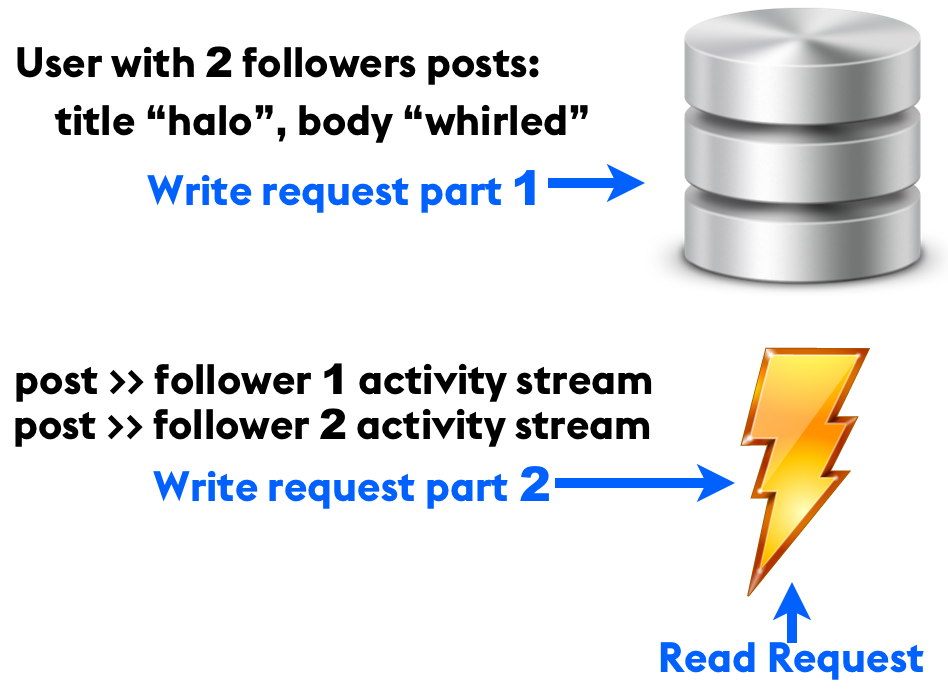
Stockage typique avec cache.
Les écritures de l’application sont plus compliquées. Disons qu’un utilisateur avec deux « followers » écrit un nouveau message. La première chose qui se passe est que les données du message sont enregistrées dans la partie stockage. Une fois que c’est fait, une tâche en arrière-plan ajoute ce post dans la version en cache du flux d’activité des deux utilisateurs qui suivent l’auteur.
Ce schéma est assez commun. Twitter conserve l’activité récente des flux d’activité des utilisateurs dans un cache en mémoire vive, qu’ils complètent quand quelqu’un qu’ils suivent poste quelque chose. Même les applications plus petites qui utilisent une sorte de flux d’activité font la même chose (rappelez-vous : jointure à sept tables).
Retour à notre exemple. Quand l’auteur modifie un message existant, la procédure de mise à jour est essentiellement la même que pour une créaton, excepté qu’au lieu d’ajouter le post au cache, on modifie l’item qui est déjà présente.
Que ce passe-t-il quand l’étape 2, le travail en arrière-plan, foire en cours de route ? Machines redémarrées, câbles réseaux débranchés, redémarrages d’applications. L’instabilité est la seule constante dans notre travail. Quand ça arrive, vous finissez avec des données invalides dans votre cache. Certaines copies du message auront l’ancien titre, certaines copies auront le nouveau. C’est un problème sévère, mais avec un cache, y’a toujours la solution nucléaire.

Vous pouvez toujours supprimer l’enregistrement complet du flux d’activité et le régénérer à partir des données du stockage arrière. Ça sera sûrement lent, mais au moins c’est possible.
Et s’il n’y a pas de stockage arrière ? Et si le cache est tout ce que vous avez ?
Quand MongoDB est votre seul stockage, c’est un cache avec aucun stockage derrière. Il VA devenir inconsistant. Pas éventuellement consistant — seulement pleinement inconsistant, sans correction possible. À ce point, vous n’avez aucune option. Pas même d’option nucléaire. Vous n’avez aucun moyen de régénérer les données dans un état consistant.
Quand Diaspora a décidé de stocker les données sociales dans MongoDB, nous étions en train de « fusionner » une base de données avec un cache. Les bases de données et les caches sont deux choses très différentes. Ils ont des idées très différentes à propos de la permanence, la rapidité, la duplication, les références, l’intégrité des données.
La conversion
Une fois qu’on a découvert qu’on avait accidentellement choisi un cache pour notre base de données, qu’avons nous fait à ce propos ?
Eh bien, c’est la question à un million de dollars. Mais j’ai déjà répondu à la question à un milliard de dollars. Dans cet article j’ai parlé de la façon dont on utilisait MongoDB par rapport à la façon dont MongoDB est conçu pour être utilisé. J’ai évoqué comment toutes ces informations étaient évidentes, et l’équipe Diaspora a juste « merdé » à chercher correctement avant de faire son choix.
Mais ce n’était pas évident du tout. La documentation MongoDB nous dit à quoi elle est bonne, sans évoquer ce à quoi elle n’est pas bonne. C’est naturel, tous les projets font ça. Mais du coup, ça nous a pris six mois, beaucoup de plaintes des utilisateurs, et une bonne dose d’enquête pour découvrir que nous utilisions MongoDB de la mauvaise manière.
Il n’y avait rien à faire sinon extraire les données de MongoDB et les déplacer dans une base de données relationnelle, en traitant les données inconsistantes découvertes du mieux qu’on pouvait. La conversion des données elle-même –export de MongoDB vers MySQL– a été très simple (NdT: j’ai fait l’opération inverse à peu près aussi simplement). Pour les détails techniques, vous pouvez relire ma présentation à la conférence All Your Base 2013.
Les dommages
On avait huit mois de données de production, qui ont été converties en à peu près 1.2 millions de lignes dans MySQL. Il a fallu quatre semaines d’affilée à développer le code pour la conversion, et quand on a « appuyé sur la détente », le site principal est resté hors-ligne pendant environ deux heures. C’était plus qu’acceptable pour un projet qui était en pré-alpha. On aurait pu encore réduire le temps passé hors-ligne, mais on avait budgété pour huit heures de coupure, donc ça semblait déjà fantastique.

PAS MAL
Épilogue
Vous vous souvenez de l’application de séries TV ? C’était le cas parfait pour utiliser MongoDB. Chaque série dans un document, parfaitement indépendant. Pas de références, pas de duplication, et aucun moyen pour les données de devenir inconsistantes.
Après trois mois de développement, c’était tranquillement en train de tourner avec MongoDB. Un lundi, réunion planning hebdomadaire, le client nous a présenté une fonctionnalité qu’un de leurs investisseurs voulait : en regardant les acteurs de l’un des épisodes d’une série, ils voulaient qu’on puisse cliquer sur le nom de l’acteur et voir toute la carrière télévisuelle de l’acteur. Ils voulaient un classement chronologique de tous les épisodes des différentes séries auxquelles avaient participé un acteur.
On stockait chaque série comme un document dans MongoDB qui contenait toutes ces informations imbriquées, y compris les acteurs. Si un même acteur apparaissait dans deux différents épisodes, l’information était stockée dans deux endroits. On avait aucun moyen de dire, à part comparer les noms, si c’était la même personne. Donc pour implémenter cette fonctionnalité, il fallait parcourir chaque document pour trouver et dé-dupliquer les instances de l’acteur sur lequel l’utilisateur avait cliqué. Ouch. Au minimum, on dé-dupliquait une fois, et on maintenait un index externe des informations sur l’acteur, ce qui amène les mêmes problèmes d’invalidation qu’avec n’importe quel cache.
Vous voyez où ça va finir
Le client pensait que cette fonctionnalité était triviale. Si les données s’étaient trouvées dans une base relationnelle, ça l’aurait été. Ce n’était pas le cas, et d’abord on a tenté de convaincre les décideurs qu’ils n’en avaient pas besoin. Après avoir échoué, on a proposé des alternatives moins coûteuses, comme lier une recherche IMDB sur le nom de l’acteur. La société faisait de l’argent avec la publicité cependant, alors ils voulaient que les utilisateurs restent sur le site plutôt que sur IMDB.
Cette demande de fonctionnalité a permis de poser la question de la conversion du projet vers PostgreSQL. Après de multiples conversations supplémentaires avec le client, on a réalisé qu’ils accordaient beaucoup de valeur à relier les séries ensembles. Ils prévoyaient de voir les autres séries/épisodes sur lesquelles un même réalisateur était impliqué, et les épisodes de série diffusés le même jour qu’un autre, entre autres choses.
C’était surtout un problème de communication plutôt qu’un problème technique. Si ces conversations avaient eu lieu plus tôt, on aurait pris le temps de comprendre comment le client voyait ses données et ce qu’il voulait en faire, et on aurait procédé à la conversion plus tôt, quand il y aurait eu moins de données, et que c’était plus facile.
Toujours apprendre
J’ai appris quelque chose de cette expérience, L’utilisation idéale de MongoDB est encore plus restreinte que nos données télévisuelles. La seule chose pour laquelle il est bon est de stocker des morceaux arbitraires de JSON. « Arbitraire », dans ce contexte, signifie que vous vous foutez de ce qu’il y a dans le JSON. Vous ne regardez même pas. Il n’y a pas de schéma, même pas de schéma implicite, comme il y en avait un dans nos données. Chaque document est juste un blob dans lequel vous ne pouvez absolument pas faire d’assomptions.
À la RubyConf ce weekend, j’ai discuté avec Conrad Irwin, qui a suggéré ce cas d’usage. Il a utilisé MongoDB pour stocker des bouts de JSON arbitraires qui venaient de clients au travers d’une API. Ça a du sens. Le théorème CDP ne sert à rien quand vos données n’ont aucun sens. Mais dans des applications intéressantes, vos données ont du sens.
J’ai entendu plusieurs personnes discuter d’utiliser MongoDB pour leur application web en remplacement de MySQL ou PostgreSQL. Il n’y a aucune circonstance dans laquelle c’est une bonne idée. La flexibilité d’un schéma sonne bien à l’oreille, mais c’est seulement utile quand la structure de vos données n’a aucune valeur. Si vous avez un schéma implicite –c’est à dire, si vous attendez quelque chose du JSON– alors MongoDB est un mauvais choix. Je suggère plutôt d’utiliser hstore de PostgreSQL (apparemment plus rapide que MongoDB de toute façon), et apprendre comment faire des changements de schéma. Ce n’est pas si dur, même sur de larges tables.
Trouver la valeur
Quand vous choisissez un stockage de données, la chose la plus importante à comprendre réside où dans vos données –et où dans leurs connexions — réside la valeur. Si vous ne savez pas encore, ce qui est tout à fait compréhensible, alors choisissez quelque chose qui ne vous collera pas dans un coin. Stocker du JSON arbitraire semble flexible, mais la véritable flexibilité c’est de pouvoir facilement ajouter des fonctionnalités dont votre entreprise a besoin.
Rendre les choses importantes facile.
Merci pour la traduction (au passage très bien faite) de cet excellent article. Je me suis lancé un peu vite dans la solution MongoDB pour mon application, sans avoir pris le temps de réfléchir à ce genre de problématique. Heureusement que je n’en suis encore qu’au début…
Je me suis également posé la question avec mon application de collection de films. Tant que j’en resterais à des informations cantonnées à un seul film, tout ira bien. Mais si je veux par exemple ajouter des informations comme le réalisateur, et que je veux faire une recherche sur celui-ci, ça fonctionnera, mais le travail sera à faire côté application et pas base de données, et ça sera plus lent.
Même si MongoDB peut au final n’avoir que très peu d’usages, il reste intéressant techniquement parlant, et c’est ce qui m’a poussé à l’expérimenter.
Merci pour l’article et pour la traduction. Je ne comprends pas très bien le problème de l’application de film. Il est possible de faire une simple recherche pour avoir la liste de séries avec tel ou tel acteur : serie.find({« actor.name »: »truc »}) … ??
Cela doit dépendre de la structure de données, et de la version de MongoDB, qui s’est amélioré sur la recherche avec les nouvelles versions (j’ai rencontré ce problème avec la vieille version 2.0 de Debian Wheezy qui n’a pas de recherche full-text par exemple). Sachant qu’en plus les noms des acteurs sont stockés dans des sous-documents, pas sur que ça fonctionne, notamment si le résultat ne contient que les sous-documents en question, et pas les docs parents (à voir, j’ai malheureusement un gros dossier sur le feu, je n’ai pas le temps de vérifier moi-même). De manière générale, l’idée est… Lire la suite »
Merci pour la traduction de l’article que j’avoue n’avoir pas complètement lu.
Je me suis arrêter au moment au chapitre comment MongoDb stocke les données.
En effet, le schéma présenter est un Data Model de type Graph. Hors MongoDb est un SGBD de type NoSQL Documents.
J’ai donc arrêter ma lecture car c’est typiquement le problème lorsque l’on se force à utiliser une technologie alors qu’elle n’est pas prévu à cet effet.
Pour un réseau social, le DM Graph est effectivement l’idéal. Mais il faut alors choisir le bon moteur.
Merci beaucoup pour la traduction de ce magnifique article, j’aurais une question pensé vous que mongodb serai une bonne idée pour stocker les données de l’insee(www.insee.fr).
MERCI
Très bonne question. Honnêtement, je ne sais pas, c’est très dépendant du type de données et de l’organisation initiale qu’on veut leur donner. Pour certaines peut-être. Sans savoir quelles données, leur niveau de dépendances, et peut-être la signification qu’on veut leur donner, joker.
Merci beaucoup pour cette traduction. L’article est très instructif.
Que pensez-vous des fonctionnalités $lookup et $unwind de MongoDB qui permettent de faire des jointures dans les requêtes MongoDB ?
J’ignore si MongoDB conserve sa légendaire vitesse avec ces mécanismes mais ils permettent de mettre sur pied un modèle de données sans duplication de données et sans implémenter des jointures dans l’application.
Merci
Pour être tout à fait honnête, je n’ai pas encore pu creuser plus son utilisation, par rapport à mon travail j’ai plutôt concentré ma montée de compétences sur MySQL/MariaDB pour l’instant. Mais on a deux/trois clients qui comptent s’en servir, je vais donc devoir pousser un peu de fonte mentale à ce propos. Les développeurs de MongoDB ne sont pas non plus idiots : s’ils ont implémenté les jointures, c’est que dans certains cas d’usages qu’on leur a remonté, opérer la jointure au niveau applicatif devait coûter trop cher en performances (surtout que MongoDB est principalement utilisé avec des projets… Lire la suite »
Très instructif, merci pour cette traduction???
Waaa des conseils sur une bdd venant d’une personne qui n’a pas compris les besoins relationnels de son projet dès le départ … Ça c’est fort 🙂