
Passer d’une à plusieurs machines pour un hébergement Web
 Cet article a été publié il y a 7 ans 4 mois 27 jours, il est donc possible qu’il ne soit plus à jour. Les informations proposées sont donc peut-être expirées.
Cet article a été publié il y a 7 ans 4 mois 27 jours, il est donc possible qu’il ne soit plus à jour. Les informations proposées sont donc peut-être expirées.Je voudrais aujourd’hui partager avec vous quelques concepts et points de détails à considérer lorsque l’on décide de faire évoluer une plate-forme d’un serveur unique à plusieurs. Parce c’est très intéressant, mais vite casse-gueule.
Les points que je n’aborderai pas ou presque
Désolé mais ayant très peu l’occasion de m’occuper du réseau (ndlr : c’est moins vrai, entre temps je suis pratiquement devenu un crack en haproxy), je préfère remettre cette partie à plus tard plutôt que de vous sortir des énormités.
Également, et partiellement pour les mêmes raisons, je n’évoquerai que le strict minimum concernant le stockage physique, les problématiques pouvant être très différentes en fonction des infrastructures.
Je vais donc voir ici le serveur, notre brique de base, d’un point de vue du système d’exploitation. Virtuel ou physique importe peu aujourd’hui. Et parce que prendre un exemple connu est toujours bon, on va prendre en exemple l’hébergement d’un WordPress.
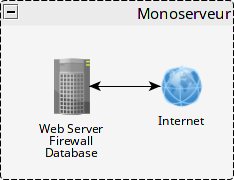
On part de ça
Pourquoi plusieurs machines déjà ?
Il y a plusieurs raisons qui peuvent vous pousser à séparer vos applicatifs sur plusieurs machines. Un cas simple qui me vient à l’esprit est de séparer la base de données du serveur Web, pour par exemple bénéficier d’un stockage SSD dédié pour la base de données, friande en entrées/sorties (encore que PHP peut facilement jouer les enquiquineurs). Cela permet à la partie Web d’avoir elle aussi plus de poumons côté disque, si vous avez un module pouvant générer des fichiers à partir de données collectées en base, vous avez lecture d’un côté, écriture de l’autre, et ça sur un seul disque même SSD on sait que c’est pas optimal.
Mais ici on ne fait au final que répartir une charge globale. Aucune redondance, et donc de haute disponibilité, qui est la deuxième raison qui peut vous pousser à disposer de plusieurs machines. En effet, avec un point d’entrée réseau capable d’envoyer les clients sur plusieurs machines, vous permettez à votre site de rester en ligne même si l’une des machines lâche méchamment (parce que les bugs ça arrive tous les jours).
Là aussi, les cas sont multiples, vous pouvez démarrer avec deux machines identiques, ou déployer plusieurs groupes de machines destinées à rendre les mêmes services : un groupe de frontaux Web, un groupe de bases de données, etc.
Ce type d’architecture permet de remplir deux objectifs : haute disponibilité comme je l’ai déjà dit, parce qu’on peut perdre un nœud dans un groupe sans mette à mal le fonctionnement et l’intégrité du site, et hautes performances, répartir le travail sur plusieurs nœuds pour un même groupe de machines. Imaginez bien que le milliard et demi de fournisseurs de données de Facebook ne sont pas servis par une seule machine même la plus puissante possible.
Je vais donc retenir deux cas : celui sans redondance, et celui avec.
Services différents sur machines différentes
Pour reprendre le cas de la base de données isolée, les contraintes se trouvent essentiellement du côté de la sécurité, notamment réseau. Dans une configuration monoserveur le service BDD n’écoute en général qu’en local, donc aucune attaque directe n’est possible. Avec deux machines il faudra s’assurer que seul le serveur Web aura le droit de communiquer avec la base de données. Cela peut passer par l’hôte de l’utilisateur, une restriction au niveau pare-feu, les choix sont multiples à ce niveau, en combiner plusieurs ne fait pas de mal.
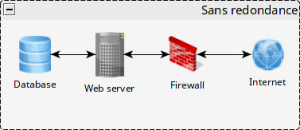 Groupe(s) de machines distinctes
Groupe(s) de machines distinctes

Là on attaque du plus lourd. Je vais m’attarder sur un cas « simple », et prendre le cas de deux serveurs Web et un serveur de base de données :
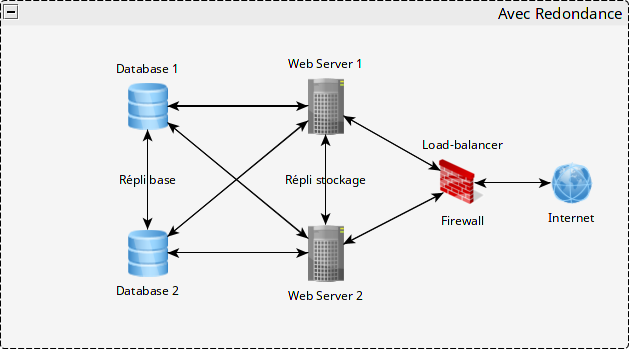
Là ça devient intéressant
Les contraintes se situent à plusieurs niveaux. D’abord, il faut absolument que les configurations, serveur Web et PHP pour ne citer que les principales, soient strictement identiques. Une règle de redirection absente sur un des deux frontaux et la moitié des requêtes ne sera potentiellement pas servie correctement, pouvant complètement bousiller le fonctionnement du site pour les visiteurs.
Deuxièmement, les fichiers. Tous les dossiers avec lesquels doit bosser votre site doivent aussi être identiques, et surtout très important, synchronisés. Là aussi le risque est grand de ne pas afficher une image une fois sur deux ce qui dans l’absolu n’est pas catastrophique, ou pire, avec un plug-in de cache opérant de l’agrégation CSS (exemple vécu au taf), voir la mise en page bousillée une fois sur deux.
Plus dangereux, le code d’un plugin influant sur la base de données, pourrait rendre le fonctionnement très instable avec deux versions différentes d’un plugin fonctionnant en parallèle.
De la théorie à la pratique
Si vous avez peu de configurations à modifier, vous pouvez vous contenter de tout faire à la main, cela demande juste d’être soigneux et de savoir travailler en miroir, Terminator étant très pratique pour ça. Le nombre de fichiers et/ou le nombre de frontaux augmentant, il est peut être temps de penser à exploiter un outil de déploiement : Puppet, Ansible, git (si si), bref, l’idée c’est de faire le taf une fois pour le pousser sur toutes les machines en même temps. Ansible et Puppet disposent de plugins permettant de faire recharger une configuration après déploiement, vous pouvez déclencher des hooks en poussant des tags sur Git (demande d’écrire le hook, plus souple si le service n’est pas « standard »), bref, y’a de quoi s’amuser franchement.
Les sessions PHP, qui sont par défaut stockées sous forme de fichiers, devraient si possible être déportées vers un système type memcache ou Redis (ce dernier semble plus facile à « clusteriser » par la suite), pourquoi pas hébergé avec la base de données. Sinon vous prenez le risque qu’entre deux chargement de pages, on vous dise que vous n’êtes pas connecté, ce qui peut être très dommageable. Certaines applications permettent de stocker les sessions en base de données, même si je ne suis pas fan du système, c’est tout à fait fonctionnel.
Le stockage par contre c’est une autre histoire. Plusieurs écoles s’affrontent, mais on retrouve globalement trois techniques : partage NFS, réplication par bloc (coucou DRBD), et réplication de système de fichiers (coucou Gluster). Le NFS est vraiment le moins fiable, je le recommanderais à la limite pour des fichiers non critiques (statiques), parce que non seulement les performances sont généralement plus mauvaises qu’un accès disque direct, mais la fiabilité n’est pas toujours au rendez-vous. J’ai eu le tour fin Juin avec un client dont TOUS les fichiers utilisés par ses différents frontaux étaient hébergés sur un seul partage NFS. Quand on a coupé le partage en question pour déplacer la machine physique qui était en dessous, bye bye les frontaux Web, et il a fallu improviser une bascule sur une page de maintenance beaucoup plus tôt que prévu.
DRBD est réputé robuste, mais a ses propres faiblesses : il ne fonctionne que dans un sens (mode master->slave), ce qui oblige à mettre en place une technologie dite de failover pour gérer en cas de coupure du principal, technologie faisant généralement appel au NFS pour que les frontaux utilisent le même volume principal, et organiser la bascule. C’est assez lourd à mettre en place, mais éprouvé.
Les réplications au niveau système de fichiers sont des dispositifs plus récents technologiquement parlant, mais semblent s’en sortir pas mal. GlusterFS est l’un d’entre eux, et dispose de beaucoup d’avantages, comme une réplication master-master (dans les deux sens), la gestion du failover intégrée, et ajouter plus de deux nœuds est un jeu d’enfant. Honnêtement c’est celui qui me paraît suffisamment sexy pour me faire dire que je vais bientôt me faire les mains dessus. D’autres technos orientées vraiment gros déploiements/datacenter comme Ceph existent aussi, mais je n’en ai vraiment pas encore l’utilité.
Malgré tout, dans l’absolu, pour ce genre de plateformes, j’ai tendance à privilégier le fait d’avoir un maximum de fichiers en local. Je m’explique : toute la logique de WordPress repose sur des fichiers PHP. Ces fichiers seront lus par les frontaux à chaque appel d’une page ou d’un contenu. Dans le cas d’une page, les différents fichiers PHP qui composent l’application vont être lus, et dans ce cas, on essaie de privilégier un accès local pour augmenter les performances. Et peu de chances qu’ils évoluent d’eux-même au fil du temps, en dehors d’une mise à jour automatique (je reviendrai dessus juste après).
En revanche, les fichiers statiques, typiquement ceux uploadés par le biais de la bibliothèque média de WP, eux sont moins critiques, et peuvent facilement se retrouver sur un stockage moins performant et/ou partagé. Donc si vous ne pouvez pas ou ne voulez pas mettre en place un stockage type GlusterFS, vous pouvez laisser en local de chaque frontal tous les fichiers de WordPress, sauf le dossier wp-content/uploads qui lui peut être un partage NFS.
PS : Récemment en continuant mes recherches pour le cas d’un client je suis tombé sur cet article (en anglais, évidemment) qui discute de csync2 et lsyncd. Je n’ai pas encore testé la solution, mais c’est une autre possibilité de synchronisation de dossier entre serveurs.
J’ai pris l’exemple de WordPress mais la même logique prévaut pour d’autres CMS, y compris le récent Ghost à la mode qui demande évidemment plus de travail que l’excellent tuto de Nicolas Simond.
Côté base de données, la réplication est le maître mot. À deux serveurs, un « simple » master-master suffit (exemple de mise en place). Au delà, il faudra se tourner vers des outils type Galera qui intègrent de manière beaucoup plus poussée la gestion en grappe rendant la mise en place et la maintenance simplifiée (on en parle en français dans ce billet).
Il y a également des cas où la réplication peut être dans un seul sens, en séparant alors les lectures et les écritures sur différents serveurs, afin d’optimiser chacun d’eux pour la tâche à accomplir.
Des contraintes supplémentaires sur votre application
À moins d’avoir un volume partagé de manière plus ou moins transparente, il convient de faire particulièrement attention aux mises à jour de votre code, car comme je l’ai évoqué le risque de se retrouver avec un comportement erratique est plus élevé.
Suivant les applications, il est peut être préférable de passer par une mise à jour « manuelle » des fichiers de l’application, plutôt que par l’interface d’administration. La plupart des CMS supportent ce mode de mise à jour et parfois les manipulations « post update » peuvent également être automatisées sans passer par l’interface. Certains frameworks disposent d’outils en ligne de commande pour lancer purge de caches, ceux basés sur symfony me viennent facilement à l’esprit, même WordPress peut être manipulé de la sorte avec WP-CLI.
Un vrai jeu de LEGO
Bref, plusieurs briques signifient plusieurs possibilités, les contraintes et attentions étant alors dépendantes du type de projet utilisé. Dans tous les cas, il existe des solutions pour redonder toute ou partie de l’infrastructure, parfois au prix d’un gros travail, parfois c’est simplifié à l’extrême. Mais c’est toujours intéressant de concevoir ce genre de plates-formes, ça peut pousser à mettre les mains dans des technologies vraiment sympa, d’apprendre aussi à mieux sécuriser sa plate-forme. En bref, s’amuser à monter un LEGO version sysadmin. Qui a dit qu’on devait rester adulte tout le temps ?
Bonjour, très intéressant, quel outil utilises-tu pour réaliser tes schema ? Bonne continuation
Bonjour
Excellent !! Plein d’infos pratique est superbement utiles.
Je vais reprendre ton idée en rajoutant la partie Ansible que je suis en train de découvrir par ailleurs.
Question a 20€ : avec quel soft fais tu tes schémas de réseau ?
Merci encore :p
J’ai trouvé c’est yEd https://www.yworks.com/products/yed
Super, merci pour l’info :p
Oui je pense que c’était pas super compliqué à trouver 🙂
J’en ferai peut-être un petit article, il est sympathique, et possède un outil très sympa pour chercher des symboles qui ne sont pas fournis de base. Et arriver, pour moi, à trouver un soft Java sympathique, faut se lever tôt 🙂