
Reprenez le contrôle du cache mémoire du noyau Linux
 Cet article a été publié il y a 8 ans 8 mois 10 jours, il est donc possible qu’il ne soit plus à jour. Les informations proposées sont donc peut-être expirées.
Cet article a été publié il y a 8 ans 8 mois 10 jours, il est donc possible qu’il ne soit plus à jour. Les informations proposées sont donc peut-être expirées.Ça m’avait manqué d’écrire un bon gros article de barbu. Bon pas si poilu que ça, mais tout de même, de temps en temps… Aujourd’hui, on parle noyau, et si j’avais déjà abordé la question du swap en matière de gestion de la mémoire, le programme d’aujourd’hui est centré sur le cache. Et surtout, comment le libérer quand effectivement monsieur le Manchot décide de gloutonner votre gentille mémoire vive pour rien. Désolé les débutants, mais ce soir, je me lâche un peu.
C’est une fois de plus dans le cadre du travail que la situation particulière s’est présentée. Le client nous « alerte » en découvrant les graphes mémoire issus de notre solution de monitoring :
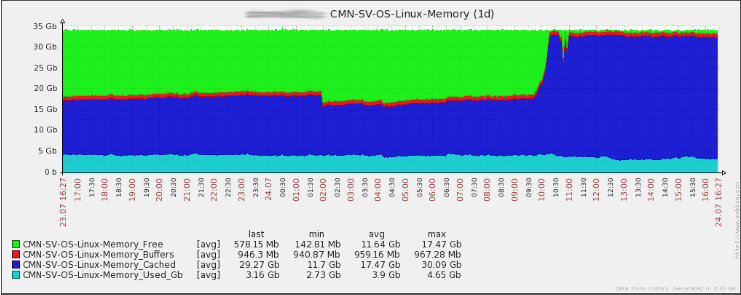
Impressionnant n’est-ce pas ? Le truc, c’est que malgré ça, aucune alerte de consommation chez nous, que ce soit disque, CPU, RAM, ou tout ça en même temps. Et surtout, la matinée a été calme : seules deux recherches de motifs sur des fichiers. Oui mais…
Rappel sur la mémoire cache du noyau
Le noyau Linux, grand chef d’orchestre de la machine, peut choisir de s’octroyer la mémoire vive restante pour divers travaux internes. Parmi eux, l’accès aux fichiers. Quand vous accédez souvent aux mêmes (typiquement en lecture), Nunux peut décider de stocker ceux-ci directement en mémoire vive plutôt que de solliciter votre disque dur à chaque fois (surtout si c’est pour éviter de le modifier).
Il peut stocker bien d’autres choses, et je vous invite à lire cet article (une fois de plus en anglais, désolé) sur l’organisation de la mémoire vive qu’on opère dans le froid. C’est lourd, mais très instructif (peut-être une traduction un jour ?). Sinon, pour consulter la mémoire cache actuellement consommée sur votre machine, vous pouvez utiliser la commande free :
|
1 2 3 4 |
$ free -m total utilisé libre partagé tamp/cache disponible Mem: 7911 3926 238 163 3745 3724 Partition d'échange: 487 0 487 |
On y voit bien la mémoire cache à droite, en avant-dernier (le vilain petit canard).
Pourquoi il est plein alors ?
On remarquera sur le graphe que les applications n’ont pas consommé un iota de RAM en plus, seul le cache a explosé. Pourquoi ?
Deux requêtes, deux recherches, lancées sur la même arborescence, contenant une chiée plus quinze de fichiers constituant plusieurs sites web, à la recherche de code malveillant. Je vous laisse les commandes ici pour les saisir sur votre infra (je les détaillerais éventuellement un jour), histoire de vous faire peur :
|
1 2 3 |
grep -Ri "eval(base64_decode" * grep -Ri "\$GLOBALS\[\$GLOBALS\[" * |
Sur le graphe, on voit qu’après la première requête, le noyau a commencé à libérer le cache. Mais j’ai lancé la deuxième commande dans la foulée sur les mêmes fichiers. Le noyau a alors considéré que ces fichiers étant accédés fréquemment, il devait en garder une copie en mémoire, et le nombre de fichiers fait que le cache a explosé. Et comme c’était la deuxième fois, il a conservé l’intégralité (ou en tout cas, tout ce qu’il pouvait pousser en RAM) en mémoire.
Une explication plus tard et la proposition de vider le cache ont rassuré le client dans les 10 minutes le temps d’analyser la chose. D’autant qu’il a d’autres problèmes bien plus grave à régler sur sa machine, ceux qui justifiaient la recherche de motif justement. Mais deux simples grep auront suffi à le faire sursauter (et à faire hausser des sourcils dans l’équipe).
Vider le cache ?
J’avais déjà montré cet avantage lors de ma présentation sur le swappiness, le noyau Linux permet d’être manipulé en temps réel sur une quantité ahurissante de paramètres, que bien peu de personnes pourraient énumérer en intégralité.
Parmi les manipulations possibles, le noyau expose, au sein de l’arborescence /sys, une entrée drop_caches à laquelle on envoie un chiffre, compris entre 1 et 3, pour sélectionner le types d’informations à virer du cache. Évidemment, il faut être root (administrateur) pour pouvoir passer ce chiffre, et donc la commande diffèrera légèrement en fonction de la situation :
|
1 2 3 4 5 |
#root echo 3 >/proc/sys/vm/drop_caches #par sudo sudo sh -c 'echo 3 >/proc/sys/vm/drop_caches' |
Personnellement, je choisis directement de tout virer (chiffre 3), de toute façon, le noyau régénèrera de lui-même les données réellement utiles dont il a besoin. On peut même aller plus loin, en lançant la routine suivante pour tenter de libérer un peu plus de choses :
|
1 2 3 4 5 6 7 8 9 10 |
free && sync && echo 3 > /proc/sys/vm/drop_caches && free total used free shared buffers cached Mem: 1018916 980832 38084 0 46924 355764 -/+ buffers/cache: 578144 440772 Swap: 2064376 128 2064248 total used free shared buffers cached Mem: 1018916 685008 333908 0 224 108252 -/+ buffers/cache: 576532 442384 Swap: 2064376 128 2064248 |
On lance un premier free, pour avoir les informations « avant », un sync qui force l’écriture des fichiers actuellement en attente en mémoire vive, puis on vide le cache, et on relance un free pour voir le résultat. Simple n’est-ce pas ?
Et si on fouillait dedans ?
Supprimer le cache, c’est bien, le scruter directement, c’est mieux ! Et pour ça, on dispose d’un outil assez intéressant, bien que compliqué à mettre en place : fincore. En effet, c’est un outil dont les sources à compiler se trouvent pour l’instant sur Google Code et qui va extraire le contenu de la mémoire. Et parfois, il se trouve au sein du paquet linux-ftools suivant votre distribution. Pas toujours simple.
Il va de soit qu’il faudra être root pour lancer un tel utilitaire. Pour chercher quels fichiers d’un dossier sont « cachés », il suffit de vous rendre dans celui-ci, et de lancer fincore :
|
1 |
fincore --pages=false --summarize --only-cached * |
Le résultat dépendra grandement de l’activité liée au dossier que vous aurez indiqué. Je n’ai malheureusement pas réussi à le faire fonctionner, aussi bien chez moi que sur une des machines du boulot. Y’a des jours, quand ça veut pas, ça veut pas, et j’ai pas insisté plus que ça.
Intérêt ?
Garder le contrôle, et ça pourrait permettre de mettre en lumière d’éventuels problèmes de performances, notamment pour des applications qui font grandement usages de fichiers. Ce n’est pas pour rien que de multiples applications de « cache » comme Varnish, qui lui aussi stocke les contenus statiques de vos sites en RAM, existent. Ces petites puces sont bien plus rapides que les plateaux, et même les SSD ne leur arrivent pas à la cheville (et pourtant ils progressent à grand pas).
Demandez à Microsoft de vous dire comment fonctionne la mémoire de Windows, quand il mange du fichier d’échange au démarrage, et comment l’en empêcher…
« issus de notre solution de monitoring »… puis rien. J’ai l’impression qu’il manque une image. « Deux requêtes, deux recherches, lancées sur la même arborescence, contenant une chiée plus quinze de fichiers constituant plusieurs sites web… » Lapin compris ? Doit falloir combler les trous et remettre les mots dans le bon ordre 🙂 Bon, et sinon, quel intérêt de se prendre la tête avec le cache ? Le noyau sait très bien que ce n’est que du cache, et que s’il a soudainement réellement besoin de mémoire, il pourra très bien libérer du cache pour des choses plus… Lire la suite »
Oui je sais, on me l’a signalé sur Twitter le coup de l’image, mais je n’ai pas été là de la journée, je l’ai zappé, on verra ça demain matin pendant le petit déjeuner (là tout de suite, dodo). L’article n’est pas là « pour se prendre la tête », l’article est là pour que ceux qui ne sauraient pas encore comprennent le jour où ils y sont confrontés. La machine du client n’a absolument rien senti, il n’y a que ce graphe là qui a bougé. Mais tu vois, il nous a averti parce qu’il ne comprenait pas. J’ai du lui… Lire la suite »
Voilà, j’ai rajouté l’image manquante, vraiment désolé 🙂
oops, je devais être tout aussi fatigué. Mais que ce soit df, du ou
free, avec les outils GNU le paramètre -h permet souvent de convertir
les résultats dans des valeurs humainement plus lisibles. Par exemple,
1.8T plutôt que 1922728840… Mais quand nous possédons une vieille
brouette avec seulement 1G de RAM, effectivement, c’est tout de suite
moins utile XD